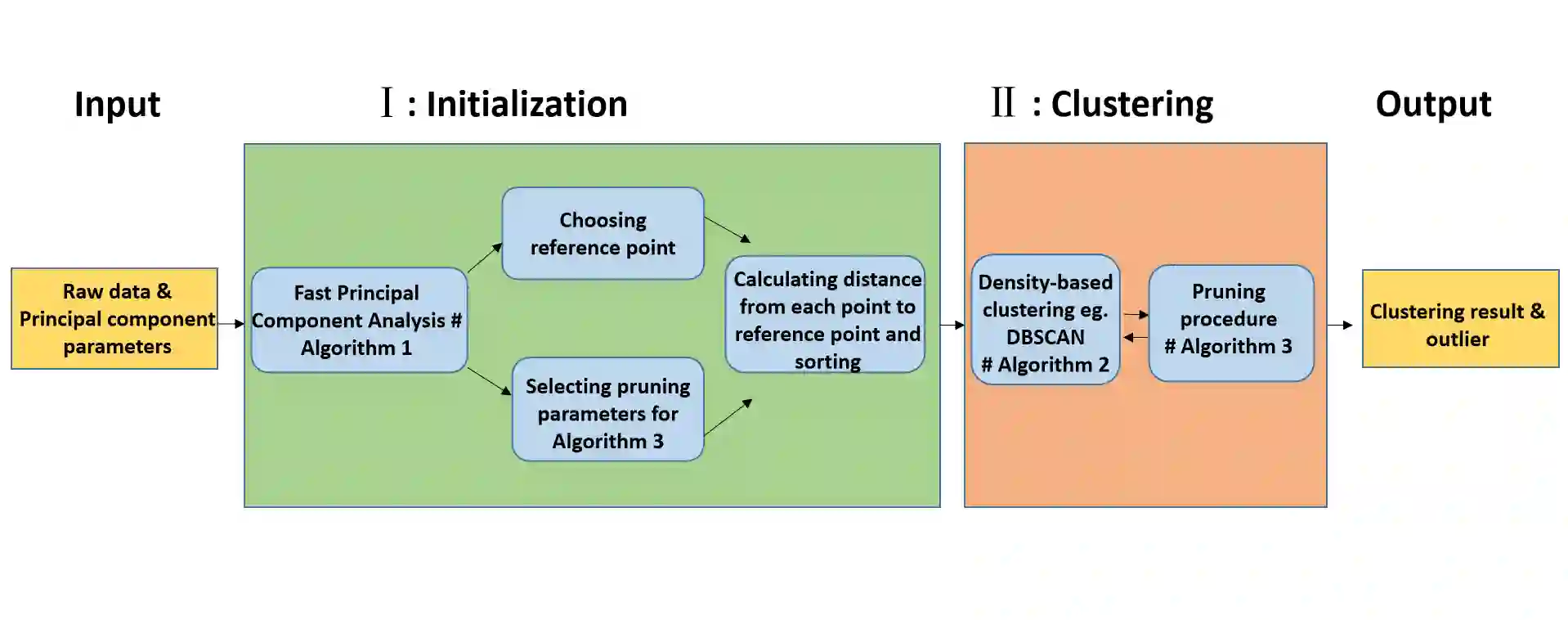
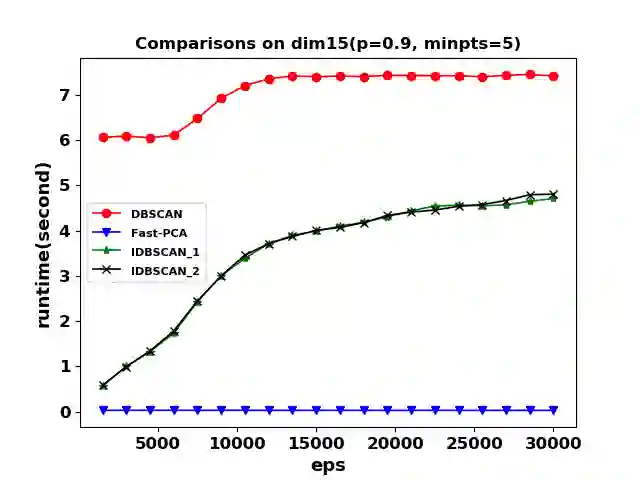
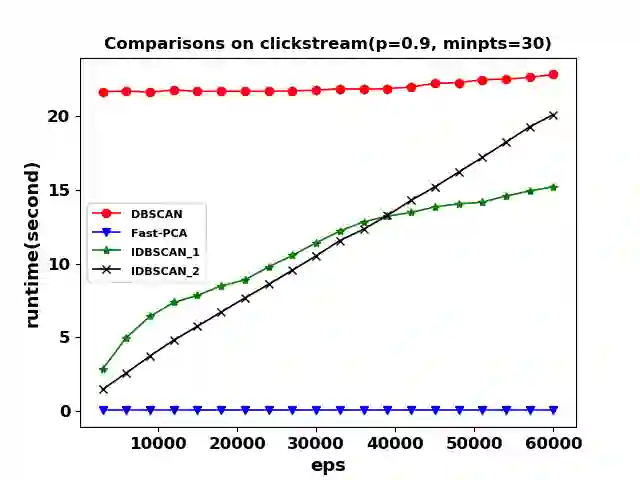
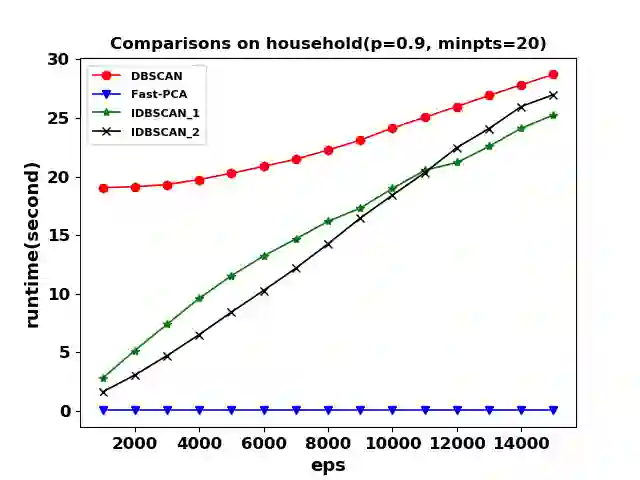
Density-based clustering algorithms are widely used for discovering clusters in pattern recognition and machine learning since they can deal with non-hyperspherical clusters and are robustness to handle outliers. However, the runtime of density-based algorithms is heavily dominated by finding neighbors and calculating the density of each point which is time-consuming. To address this issue, this paper proposes a density-based clustering framework by using the fast principal component analysis, which can be applied to density based methods to prune unnecessary distance calculations when finding neighbors and estimating densities. By applying this clustering framework to the Density Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm, an improved DBSCAN (called IDBSCAN) is obtained, which preserves the advantage of DBSCAN and meanwhile, greatly reduces the computation of redundant distances. Experiments on five benchmark datasets demonstrate that the proposed IDBSCAN algorithm improves the computational efficiency significantly.
翻译:以密度为基础的群集算法被广泛用于在模式识别和机器学习中发现群集,因为它们可以处理非同步的群集,并且具有处理离子的稳健性;然而,基于密度的算法的运行时间主要取决于寻找邻居和计算每个点的密度,而计算每个点的密度是耗时的。为解决这一问题,本文件建议采用基于密度的群集框架,采用快速主元件分析法,这种分析法可以适用于基于密度的方法,在寻找邻居和估计密度时进行不必要的远程计算。通过将这个群集框架应用于基于密度的空间集成应用的噪音算法(DBSCAN),获得了改进的DBSCAN(称为IDBSCAN),这保留了DBSCAN的优势,同时大大降低了冗余距离的计算。对五个基准数据集的实验表明,拟议的IDBSCAN算法大大改进了计算效率。