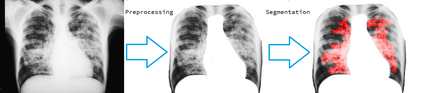
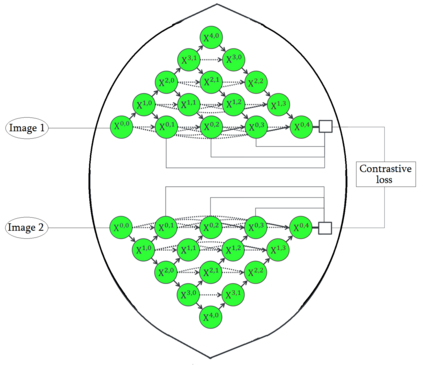
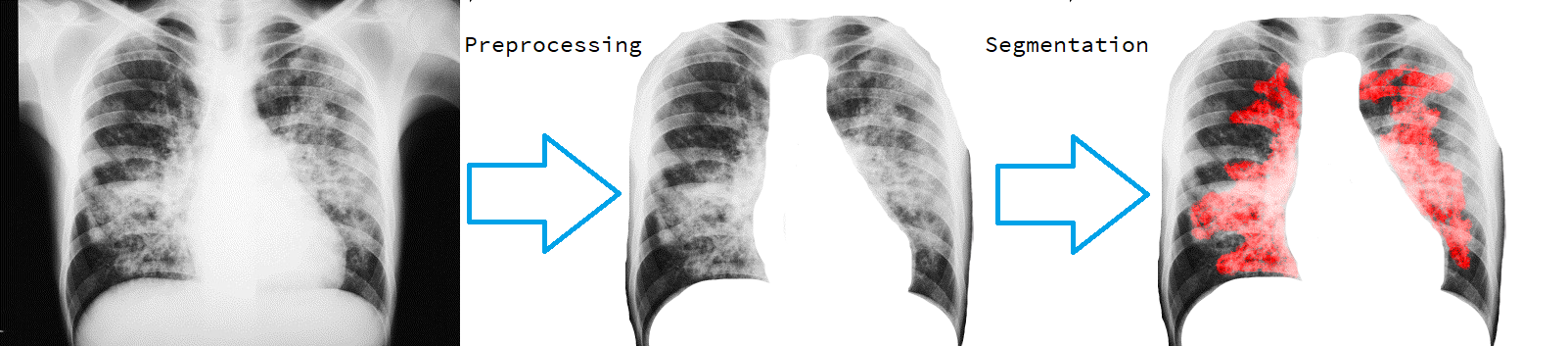
Unets have become the standard method for semantic segmentation of medical images, along with fully convolutional networks (FCN). Unet++ was introduced as a variant of Unet, in order to solve some of the problems facing Unet and FCNs. Unet++ provided networks with an ensemble of variable depth Unets, hence eliminating the need for professionals estimating the best suitable depth for a task. While Unet and all its variants, including Unet++ aimed at providing networks that were able to train well without requiring large quantities of annotated data, none of them attempted to eliminate the need for pixel-wise annotated data altogether. Obtaining such data for each disease to be diagnosed comes at a high cost. Hence such data is scarce. In this paper we use contrastive learning to train Unet++ for semantic segmentation of medical images using medical images from various sources including magnetic resonance imaging (MRI) and computed tomography (CT), without the need for pixel-wise annotations. Here we describe the architecture of the proposed model and the training method used. This is still a work in progress and so we abstain from including results in this paper. The results and the trained model would be made available upon publication or in subsequent versions of this paper on arxiv.
翻译:Unet++ 被引入为Unet的变体,目的是解决Unet和FCNs面临的一些问题。 Unet++ 向网络提供了可变深度Unet+ 的组合,从而消除了专业人员估计某种任务的最佳深度的必要性。尽管Unet及其所有变体,包括Unet+++,旨在提供能够在不需要大量附加说明的数据的情况下进行良好培训的网络,但没有一个试图完全消除对像素的附加说明数据的需求。为每种疾病获得这类数据的成本很高。因此,这类数据十分稀少。在本文中,我们使用对比性学习来培训Unet++,利用各种来源的医疗图像,包括磁共振成像和计算成像(CT)对医疗图像进行语解分解,而不需要像素的描述。这里我们描述的是拟议模型的结构和使用的培训方法。这仍然是一项进展中的工作,因此我们无法在随后的纸张版本中获取结果。