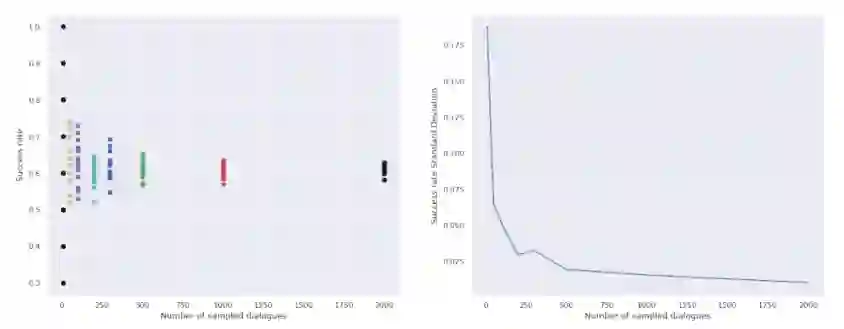
End-to-end multi-task dialogue systems are usually designed with separate modules for the dialogue pipeline. Among these, the policy module is essential for deciding what to do in response to user input. This policy is trained by reinforcement learning algorithms by taking advantage of an environment in which an agent receives feedback in the form of a reward signal. The current dialogue systems, however, only provide meagre and simplistic rewards. Investigating intrinsic motivation reinforcement learning algorithms is the goal of this study. Through this, the agent can quickly accelerate training and improve its capacity to judge the quality of its actions by teaching it an internal incentive system. In particular, we adapt techniques for random network distillation and curiosity-driven reinforcement learning to measure the frequency of state visits and encourage exploration by using semantic similarity between utterances. Experimental results on MultiWOZ, a heterogeneous dataset, show that intrinsic motivation-based debate systems outperform policies that depend on extrinsic incentives. By adopting random network distillation, for example, which is trained using semantic similarity between user-system dialogues, an astounding average success rate of 73% is achieved. This is a significant improvement over the baseline Proximal Policy Optimization (PPO), which has an average success rate of 60%. In addition, performance indicators such as booking rates and completion rates show a 10% rise over the baseline. Furthermore, these intrinsic incentive models help improve the system's policy's resilience in an increasing amount of domains. This implies that they could be useful in scaling up to settings that cover a wider range of domains.
翻译:暂无翻译