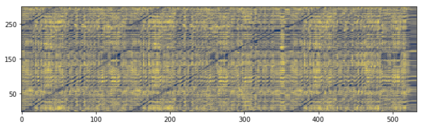
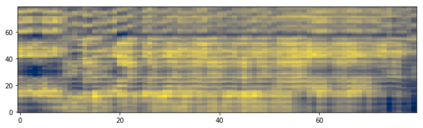
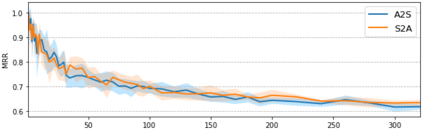
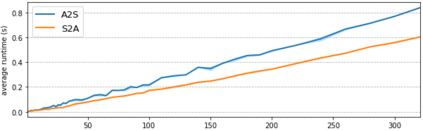
This paper addresses the problem of cross-modal musical piece identification and retrieval: finding the appropriate recording(s) from a database given a sheet music query, and vice versa, working directly with audio and scanned sheet music images. The fundamental approach to this is to learn a cross-modal embedding space with a suitable similarity structure for audio and sheet image snippets, using a deep neural network, and identifying candidate pieces by cross-modal near neighbour search in this space. However, this method is oblivious of temporal aspects of music. In this paper, we introduce two strategies that address this shortcoming. First, we present a strategy that aligns sequences of embeddings learned from sheet music scans and audio snippets. A series of experiments on whole piece and fragment-level retrieval on 24 hours worth of classical piano recordings demonstrates significant improvement. Second, we show that the retrieval can be further improved by introducing an attention mechanism to the embedding learning model that reduces the effects of tempo variations in music. To conclude, we assess the scalability of our method and discuss potential measures to make it suitable for truly large-scale applications.
翻译:本文论述跨模式音乐片的识别和检索问题:从数据库中找到一个有单曲的音乐查询单中的适当记录,反之亦然,直接使用音频和扫描单片音乐图像。 这样做的基本办法是学习一个跨模式嵌入空间,对音频和片片图像片段采用适当的类似结构,使用深层神经网络,并通过在空间中近邻的跨模式搜索来识别候选片段。然而,这种方法对音乐的时间方面是模糊的。在本文中,我们引入了两个解决这一缺陷的战略。 首先,我们介绍了一个战略,将从单曲扫描和音频片中学习的嵌入序列相匹配。一系列关于整片和碎片级检索的实验,值得古典钢琴录音24小时进行,都取得了显著的改进。 其次,我们表明,通过引入一个关注机制来嵌入学习模型以减少音乐节变效应的影响,可以进一步改进检索工作。最后,我们评估我们的方法的可扩展性,并讨论使其适合真正大规模应用的潜在措施。