
题目: Exploring and Distilling Cross-Modal Information for Image Captioning
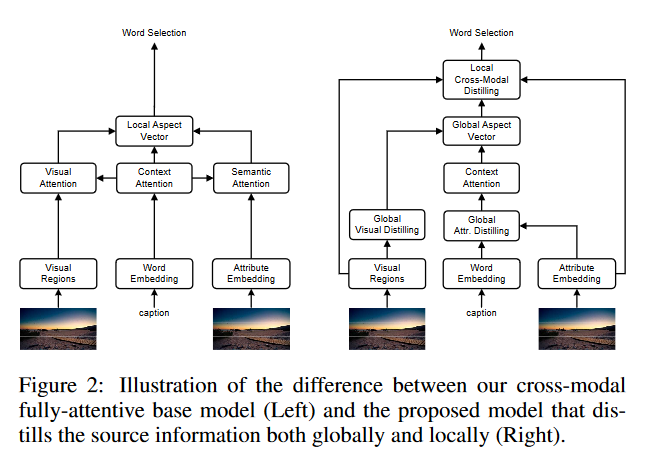
摘要: 近年来,基于注意力的编解码模型在图像字幕中得到了广泛的应用。然而,目前的图像理解方法还存在很大的困难。在这项工作中,我们认为这种理解需要对相关图像区域的视觉注意和对相关属性的语义注意。为了实现有效的注意,我们从跨模态的角度对图像字幕进行了研究,提出了一种全局和局部信息挖掘和提取的方法,对视觉和语言中的源信息进行挖掘和提取。它通过提取图像的显著区域组和属性搭配,全局地提供基于标题上下文的图像空间和关系表示形式aspect vector,并参照aspect vector局部地提取细粒度区域和属性进行选词。我们的全神贯注模型在COCO测试集上的离线COCO评估中获得了129.3分的CIDEr分数,在准确性、速度和参数预算方面都有显著的效率。

成为VIP会员查看完整内容
相关内容

专知会员服务
102+阅读 · 2019年11月24日
Arxiv
5+阅读 · 2018年4月3日


相关VIP内容
专知会员服务
102+阅读 · 2019年11月24日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年4月3日