【论文推荐】最新八篇视频描述生成相关论文—在线视频理解、联合定位和描述事件、生成视频、跨模态注意力机制、联合事件检测和描述
【导读】专知内容组整理近期八篇视频描述生成(Video Captioning)相关文章,为大家进行介绍,欢迎查看!
1.Amortized Context Vector Inference for Sequence-to-Sequence Networks(序列-序列网络的平摊上下文矢量推断)
作者:Sotirios Chatzis,Aristotelis Charalampous,Kyriacos Tolias,Sotiris A. Vassou
机构:Cyprus University of Technology
摘要:Neural attention (NA) is an effective mechanism for inferring complex structural data dependencies that span long temporal horizons. As a consequence, it has become a key component of sequence-to-sequence models that yield state-of-the-art performance in as hard tasks as abstractive document summarization (ADS), machine translation (MT), and video captioning (VC). NA mechanisms perform inference of context vectors; these constitute weighted sums of deterministic input sequence encodings, adaptively sourced over long temporal horizons. However, recent work in the field of amortized variational inference (AVI) has shown that it is often useful to treat the representations generated by deep networks as latent random variables. This allows for the models to better explore the space of possible representations. Based on this motivation, in this work we introduce a novel regard towards a popular NA mechanism, namely soft-attention (SA). Our approach treats the context vectors generated by SA models as latent variables, the posteriors of which are inferred by employing AVI. Both the means and the covariance matrices of the inferred posteriors are parameterized via deep network mechanisms similar to those employed in the context of standard SA. To illustrate our method, we implement it in the context of popular sequence-to-sequence model variants with SA. We conduct an extensive experimental evaluation using challenging ADS, VC, and MT benchmarks, and show how our approach compares to the baselines.
期刊:arXiv, 2018年6月1日
网址:
http://www.zhuanzhi.ai/document/d102cfcd360d88726253b364e3a489d8
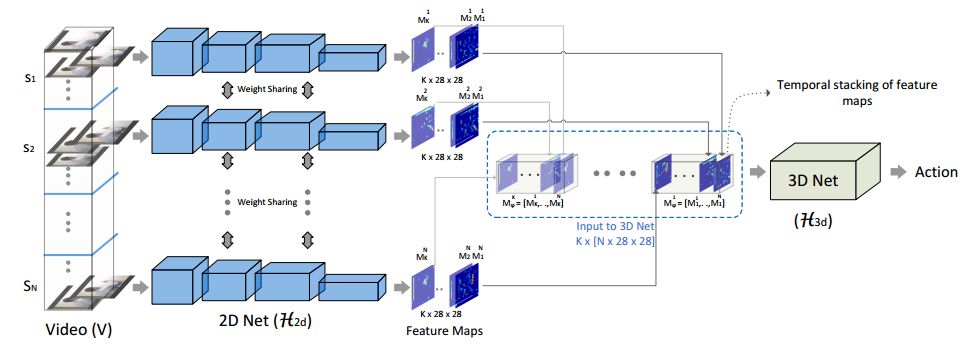
2.ECO: Efficient Convolutional Network for Online Video Understanding(ECO:基于高效卷积网络的在线视频理解)
作者:Mohammadreza Zolfaghari,Kamaljeet Singh,Thomas Brox
Submitted to ECCV 2018.
机构:University of Freiburg
摘要:The state of the art in video understanding suffers from two problems: (1) The major part of reasoning is performed locally in the video, therefore, it misses important relationships within actions that span several seconds. (2) While there are local methods with fast per-frame processing, the processing of the whole video is not efficient and hampers fast video retrieval or online classification of long-term activities. In this paper, we introduce a network architecture that takes long-term content into account and enables fast per-video processing at the same time. The architecture is based on merging long-term content already in the network rather than in a post-hoc fusion. Together with a sampling strategy, which exploits that neighboring frames are largely redundant, this yields high-quality action classification and video captioning at up to 230 videos per second, where each video can consist of a few hundred frames. The approach achieves competitive performance across all datasets while being 10x to 80x faster than state-of-the-art methods.
期刊:arXiv, 2018年5月7日
网址:
http://www.zhuanzhi.ai/document/6568469aff526a9674ad5ebb3675fee3
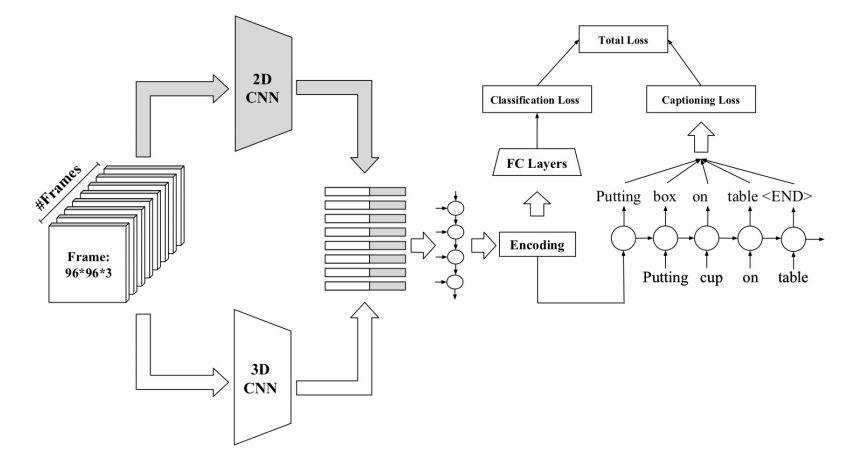
3.Fine-grained Video Classification and Captioning(细粒度的视频分类和描述生成)
作者:Farzaneh Mahdisoltani,Guillaume Berger,Waseem Gharbieh,David Fleet,Roland Memisevic
机构:University of Toronto
摘要:We describe a DNN for fine-grained action classification and video captioning. It gives state-of-the-art performance on the challenging Something-Something dataset, with over 220, 000 videos and 174 fine-grained actions. Classification and captioning on this dataset are challenging because of the subtle differences between actions, the use of thousands of different objects, and the diversity of captions penned by crowd actors. The model architecture shares features for classification and captioning, and is trained end-to-end. It performs much better than the existing classification benchmark for Something-Something, with impressive fine-grained results, and it yields a strong baseline on the new Something-Something captioning task. Our results reveal that there is a strong correlation between the degree of detail in the task and the ability of the learned features to transfer to other tasks.
期刊:arXiv, 2018年4月25日
网址:
http://www.zhuanzhi.ai/document/3bcf0f7c4788e02c8c9fd5459803465b
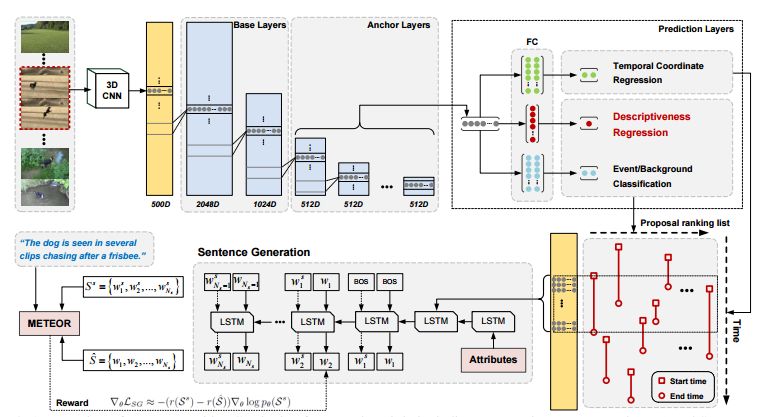
4.Jointly Localizing and Describing Events for Dense Video Captioning(联合定位和描述事件进行密集的视频描述生成)
作者:Yehao Li,Ting Yao,Yingwei Pan,Hongyang Chao,Tao Mei
CVPR 2018 Spotlight, Rank 1 in ActivityNet Captions Challenge 2017
机构:Sun Yat-sen University,University of Science and Technology of China
摘要:Automatically describing a video with natural language is regarded as a fundamental challenge in computer vision. The problem nevertheless is not trivial especially when a video contains multiple events to be worthy of mention, which often happens in real videos. A valid question is how to temporally localize and then describe events, which is known as "dense video captioning." In this paper, we present a novel framework for dense video captioning that unifies the localization of temporal event proposals and sentence generation of each proposal, by jointly training them in an end-to-end manner. To combine these two worlds, we integrate a new design, namely descriptiveness regression, into a single shot detection structure to infer the descriptive complexity of each detected proposal via sentence generation. This in turn adjusts the temporal locations of each event proposal. Our model differs from existing dense video captioning methods since we propose a joint and global optimization of detection and captioning, and the framework uniquely capitalizes on an attribute-augmented video captioning architecture. Extensive experiments are conducted on ActivityNet Captions dataset and our framework shows clear improvements when compared to the state-of-the-art techniques. More remarkably, we obtain a new record: METEOR of 12.96% on ActivityNet Captions official test set.
期刊:arXiv, 2018年4月23日
网址:
http://www.zhuanzhi.ai/document/e53e79b7fe6fa7846262e86ba15ea5d2
5.To Create What You Tell: Generating Videos from Captions(To Create What You Tell:从描述生成视频)
作者:Yingwei Pan,Zhaofan Qiu,Ting Yao,Houqiang Li,Tao Mei
ACM MM 2017 Brave New Idea
机构:University of Science and Technology of China
摘要:We are creating multimedia contents everyday and everywhere. While automatic content generation has played a fundamental challenge to multimedia community for decades, recent advances of deep learning have made this problem feasible. For example, the Generative Adversarial Networks (GANs) is a rewarding approach to synthesize images. Nevertheless, it is not trivial when capitalizing on GANs to generate videos. The difficulty originates from the intrinsic structure where a video is a sequence of visually coherent and semantically dependent frames. This motivates us to explore semantic and temporal coherence in designing GANs to generate videos. In this paper, we present a novel Temporal GANs conditioning on Captions, namely TGANs-C, in which the input to the generator network is a concatenation of a latent noise vector and caption embedding, and then is transformed into a frame sequence with 3D spatio-temporal convolutions. Unlike the naive discriminator which only judges pairs as fake or real, our discriminator additionally notes whether the video matches the correct caption. In particular, the discriminator network consists of three discriminators: video discriminator classifying realistic videos from generated ones and optimizes video-caption matching, frame discriminator discriminating between real and fake frames and aligning frames with the conditioning caption, and motion discriminator emphasizing the philosophy that the adjacent frames in the generated videos should be smoothly connected as in real ones. We qualitatively demonstrate the capability of our TGANs-C to generate plausible videos conditioning on the given captions on two synthetic datasets (SBMG and TBMG) and one real-world dataset (MSVD). Moreover, quantitative experiments on MSVD are performed to validate our proposal via Generative Adversarial Metric and human study.
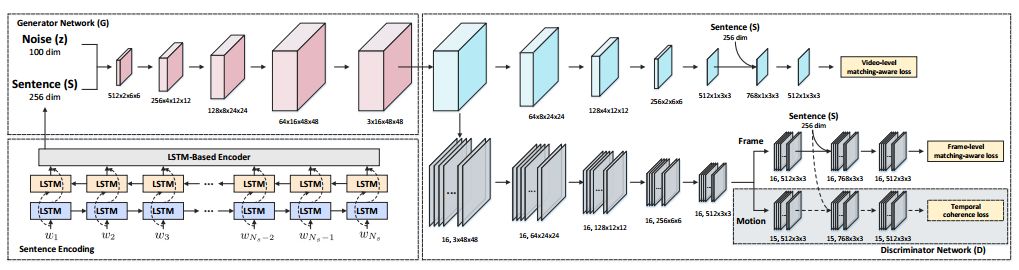
期刊:arXiv, 2018年4月23日
网址:
http://www.zhuanzhi.ai/document/da3dfd668f4254a8dc01894d5d4db3e1
6.Watch, Listen, and Describe: Globally and Locally Aligned Cross-Modal Attentions for Video Captioning(Watch, Listen, and Describe:基于全局和局部对齐的跨模态注意力机制的视频描述生成)
作者:Xin Wang,Yuan-Fang Wang,William Yang Wang
NAACL 2018
机构:University of California
摘要:A major challenge for video captioning is to combine audio and visual cues. Existing multi-modal fusion methods have shown encouraging results in video understanding. However, the temporal structures of multiple modalities at different granularities are rarely explored, and how to selectively fuse the multi-modal representations at different levels of details remains uncharted. In this paper, we propose a novel hierarchically aligned cross-modal attention (HACA) framework to learn and selectively fuse both global and local temporal dynamics of different modalities. Furthermore, for the first time, we validate the superior performance of the deep audio features on the video captioning task. Finally, our HACA model significantly outperforms the previous best systems and achieves new state-of-the-art results on the widely used MSR-VTT dataset.
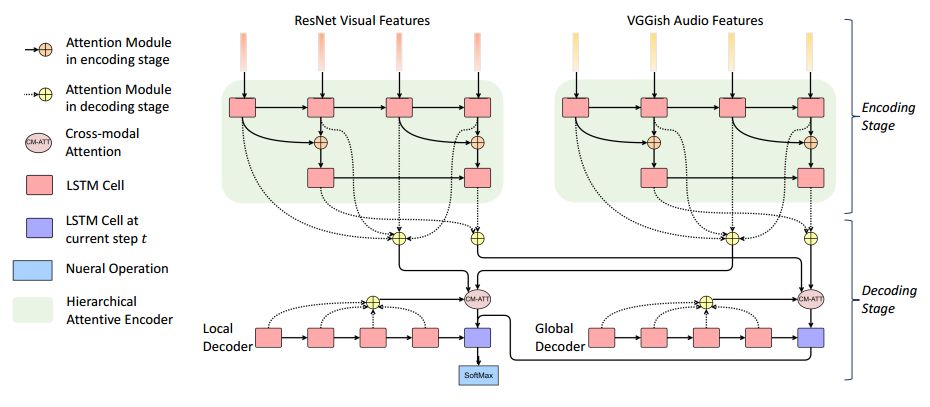
期刊:arXiv, 2018年4月16日
网址:
http://www.zhuanzhi.ai/document/bfbe5e00bdc5f701f975b4c1e7f20133
7.Joint Event Detection and Description in Continuous Video Streams(连续视频流中的联合事件检测和描述)
作者:Huijuan Xu,Boyang Li,Vasili Ramanishka,Leonid Sigal,Kate Saenko
机构:University of British Columbia,Boston University
摘要:Dense video captioning is a fine-grained video understanding task that involves two sub-problems: localizing distinct events in a long video stream, and generating captions for the localized events. We propose the Joint Event Detection and Description Network (JEDDi-Net), which solves the dense video captioning task in an end-to-end fashion. Our model continuously encodes the input video stream with three-dimensional convolutional layers, proposes variable-length temporal events based on pooled features, and generates their captions. Unlike existing approaches, our event proposal generation and language captioning networks are trained jointly and end-to-end, allowing for improved temporal segmentation. In order to explicitly model temporal relationships between visual events and their captions in a single video, we also propose a two-level hierarchical captioning module that keeps track of context. On the large-scale ActivityNet Captions dataset, JEDDi-Net demonstrates improved results as measured by standard metrics. We also present the first dense captioning results on the TACoS-MultiLevel dataset.
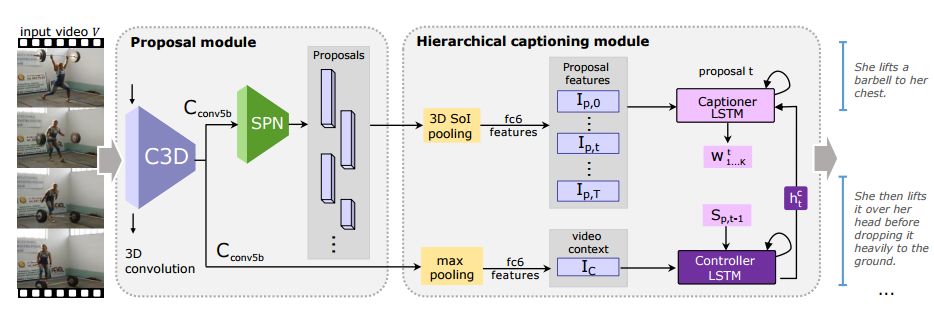
期刊:arXiv, 2018年4月14日
网址:
http://www.zhuanzhi.ai/document/b8cf460ea65445597b48299cc2624365
8.Text-to-Clip Video Retrieval with Early Fusion and Re-Captioning(文本到剪辑视频检索与早期融合和再生成)
作者:Huijuan Xu,Kun He,Leonid Sigal,Stan Sclaroff,Kate Saenko
机构:University of British Columbia,Boston University
摘要:We propose a novel method capable of retrieving clips from untrimmed videos based on natural language queries. This cross-modal retrieval task plays a key role in visual-semantic understanding, and requires localizing clips in time and computing their similarity to the query sentence. Current methods generate sentence and video embeddings and then compare them using a late fusion approach, but this ignores the word order in queries and prevents more fine-grained comparisons. Motivated by the need for fine-grained multi-modal feature fusion, we propose a novel early fusion embedding approach that combines video and language information at the word level. Furthermore, we use the inverse task of dense video captioning as a side-task to improve the learned embedding. Our full model combines these components with an efficient proposal pipeline that performs accurate localization of potential video clips. We present a comprehensive experimental validation on two large-scale text-to-clip datasets (Charades-STA and DiDeMo) and attain state-of-the-art retrieval results with our model.
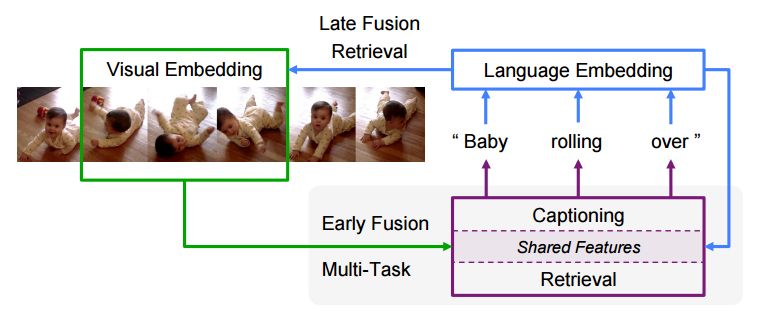
期刊:arXiv, 2018年4月14日
网址:
http://www.zhuanzhi.ai/document/6c593dcc0b93b9df5d9ab20bade3620c
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知


