【论文推荐】最新六篇知识图谱相关论文—事件演化图、神经词义消歧、增强神经网络、Mem2Seq、用户偏好传播、概率嵌入
【导读】专知内容组既前两天推出十五篇知识图谱(Knowledge Graph)相关论文,今天为大家推出六篇知识图谱(Knowledge Graph)相关论文,欢迎查看!
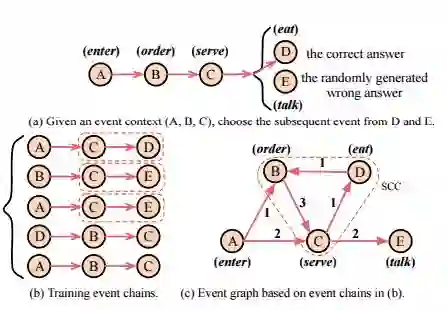
16.Constructing Narrative Event Evolutionary Graph for Script Event Prediction(构建叙事事件演化图进行脚本事件预测)
作者:Zhongyang Li,Xiao Ding,Ting Liu
摘要:Script event prediction requires a model to predict the subsequent event given an existing event context. Previous models based on event pairs or event chains cannot make full use of dense event connections, which may limit their capability of event prediction. To remedy this, we propose constructing an event graph to better utilize the event network information for script event prediction. In particular, we first extract narrative event chains from large quantities of news corpus, and then construct a narrative event evolutionary graph (NEEG) based on the extracted chains. NEEG can be seen as a knowledge base that describes event evolutionary principles and patterns. To solve the inference problem on NEEG, we present a scaled graph neural network (SGNN) to model event interactions and learn better event representations. Instead of computing the representations on the whole graph, SGNN processes only the concerned nodes each time, which makes our model feasible to large-scale graphs. By comparing the similarity between input context event representations and candidate event representations, we can choose the most reasonable subsequent event. Experimental results on widely used New York Times corpus demonstrate that our model significantly outperforms state-of-the-art baseline methods, by using standard multiple choice narrative cloze evaluation.
期刊:arXiv, 2018年5月16日
网址:
http://www.zhuanzhi.ai/document/c7b67a8e4c03a050d0b525890841732d
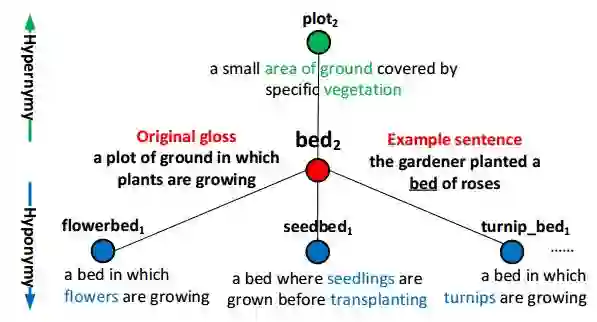
17.Incorporating Glosses into Neural Word Sense Disambiguation(在神经词义消歧中引入Glosses)
作者:Fuli Luo,Tianyu Liu,Qiaolin Xia,Baobao Chang,Zhifang Sui
机构:Peking University
摘要:Word Sense Disambiguation (WSD) aims to identify the correct meaning of polysemous words in the particular context. Lexical resources like WordNet which are proved to be of great help for WSD in the knowledge-based methods. However, previous neural networks for WSD always rely on massive labeled data (context), ignoring lexical resources like glosses (sense definitions). In this paper, we integrate the context and glosses of the target word into a unified framework in order to make full use of both labeled data and lexical knowledge. Therefore, we propose GAS: a gloss-augmented WSD neural network which jointly encodes the context and glosses of the target word. GAS models the semantic relationship between the context and the gloss in an improved memory network framework, which breaks the barriers of the previous supervised methods and knowledge-based methods. We further extend the original gloss of word sense via its semantic relations in WordNet to enrich the gloss information. The experimental results show that our model outperforms the state-of-theart systems on several English all-words WSD datasets.
期刊:arXiv, 2018年5月21日
网址:
http://www.zhuanzhi.ai/document/8191598c72c9d6fdfbd110dca181bd25
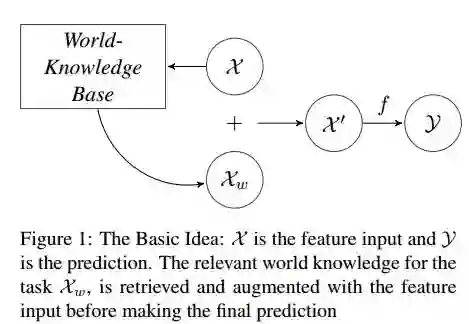
18.Learning beyond datasets: Knowledge Graph Augmented Neural Networks for Natural language Processing(Learning beyond datasets:基于知识图谱增强神经网络的自然语言处理)
作者:K M Annervaz,Somnath Basu Roy Chowdhury,Ambedkar Dukkipati
摘要:Machine Learning has been the quintessential solution for many AI problems, but learning is still heavily dependent on the specific training data. Some learning models can be incorporated with a prior knowledge in the Bayesian set up, but these learning models do not have the ability to access any organised world knowledge on demand. In this work, we propose to enhance learning models with world knowledge in the form of Knowledge Graph (KG) fact triples for Natural Language Processing (NLP) tasks. Our aim is to develop a deep learning model that can extract relevant prior support facts from knowledge graphs depending on the task using attention mechanism. We introduce a convolution-based model for learning representations of knowledge graph entity and relation clusters in order to reduce the attention space. We show that the proposed method is highly scalable to the amount of prior information that has to be processed and can be applied to any generic NLP task. Using this method we show significant improvement in performance for text classification with News20, DBPedia datasets and natural language inference with Stanford Natural Language Inference (SNLI) dataset. We also demonstrate that a deep learning model can be trained well with substantially less amount of labeled training data, when it has access to organised world knowledge in the form of knowledge graph.
期刊:arXiv, 2018年5月21日
网址:
http://www.zhuanzhi.ai/document/f791356ac2fb2e8c710654bf37872a9e
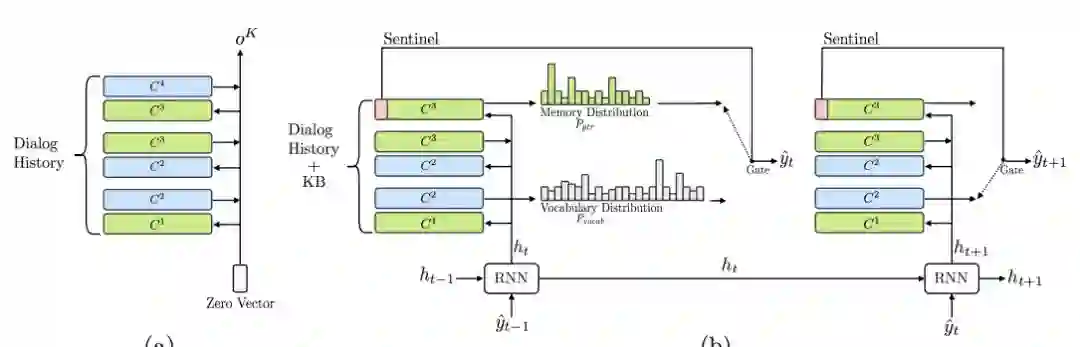
19.Mem2Seq: Effectively Incorporating Knowledge Bases into End-to-End Task-Oriented Dialog Systems(Mem2Seq:有效地将知识库集成到端到端面向任务的对话系统中)
作者:Andrea Madotto,Chien-Sheng Wu,Pascale Fung
机构:The Hong Kong University of Science and Technology
摘要:End-to-end task-oriented dialog systems usually suffer from the challenge of incorporating knowledge bases. In this paper, we propose a novel yet simple end-to-end differentiable model called memory-to-sequence (Mem2Seq) to address this issue. Mem2Seq is the first neural generative model that combines the multi-hop attention over memories with the idea of pointer network. We empirically show how Mem2Seq controls each generation step, and how its multi-hop attention mechanism helps in learning correlations between memories. In addition, our model is quite general without complicated task-specific designs. As a result, we show that Mem2Seq can be trained faster and attain the state-of-the-art performance on three different task-oriented dialog datasets.
期刊:arXiv, 2018年5月21日
网址:
http://www.zhuanzhi.ai/document/ef193d26d0c5f1efc51107fcde8a2163
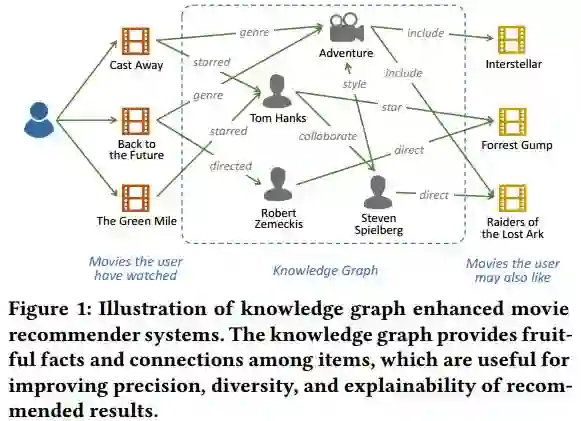
20.Ripple Network: Propagating User Preferences on the Knowledge Graph for Recommender Systems(Ripple Network:基于知识图谱用户偏好传播的推荐系统)
作者:Hongwei Wang,Fuzheng Zhang,Jialin Wang,Miao Zhao,Wenjie Li,Xing Xie,Minyi Guo
机构:Shanghai Jiao Tong University
摘要:To address the sparsity and cold start problem of collaborative filtering, researchers usually make use of side information, such as social networks or item attributes, to improve recommendation performance. This paper considers the knowledge graph as the source of side information. To address the limitations of existing embedding-based and path-based methods for knowledge-graph-aware recommendation, we propose Ripple Network, an end-to-end framework that naturally incorporates the knowledge graph into recommender systems. Similar to actual ripples propagating on the surface of water, Ripple Network stimulates the propagation of user preferences over the set of knowledge entities by automatically and iteratively extending a user's potential interests along links in the knowledge graph. The multiple "ripples" activated by a user's historically clicked items are thus superposed to form the preference distribution of the user with respect to a candidate item, which could be used for predicting the final clicking probability. Through extensive experiments on real-world datasets, we demonstrate that Ripple Network achieves substantial gains in a variety of scenarios, including movie, book and news recommendation, over several state-of-the-art baselines.
期刊:arXiv, 2018年5月19日
网址:
http://www.zhuanzhi.ai/document/558bf35c10884918711cb0166c8bdae4
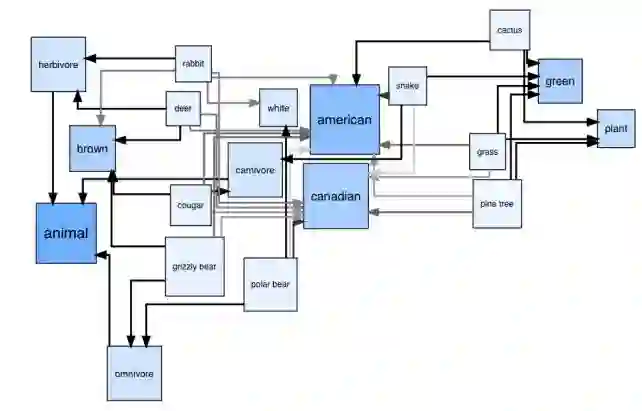
21.Probabilistic Embedding of Knowledge Graphs with Box Lattice Measures(用框格度量知识图谱的概率嵌入)
作者:Luke Vilnis,Xiang Li,Shikhar Murty,Andrew McCallum
机构:University of Massachusetts Amherst
摘要:Embedding methods which enforce a partial order or lattice structure over the concept space, such as Order Embeddings (OE) (Vendrov et al., 2016), are a natural way to model transitive relational data (e.g. entailment graphs). However, OE learns a deterministic knowledge base, limiting expressiveness of queries and the ability to use uncertainty for both prediction and learning (e.g. learning from expectations). Probabilistic extensions of OE (Lai and Hockenmaier, 2017) have provided the ability to somewhat calibrate these denotational probabilities while retaining the consistency and inductive bias of ordered models, but lack the ability to model the negative correlations found in real-world knowledge. In this work we show that a broad class of models that assign probability measures to OE can never capture negative correlation, which motivates our construction of a novel box lattice and accompanying probability measure to capture anticorrelation and even disjoint concepts, while still providing the benefits of probabilistic modeling, such as the ability to perform rich joint and conditional queries over arbitrary sets of concepts, and both learning from and predicting calibrated uncertainty. We show improvements over previous approaches in modeling the Flickr and WordNet entailment graphs, and investigate the power of the model.
期刊:arXiv, 2018年5月17日
网址:
http://www.zhuanzhi.ai/document/366d92d0766f10f38a666baa361d74a4
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知




