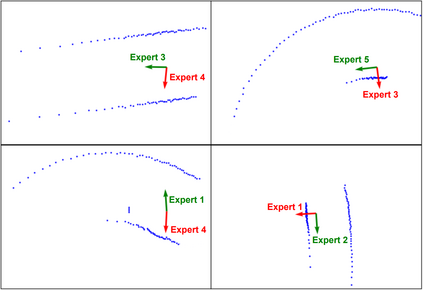
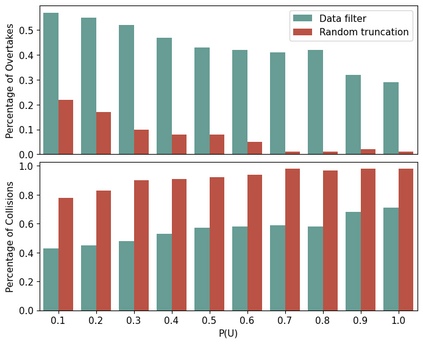
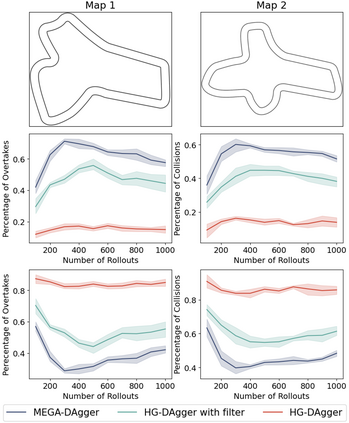
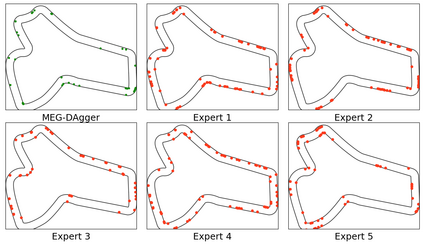
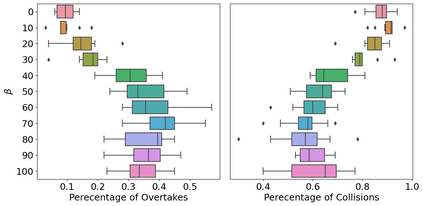
Imitation learning has been widely applied to various autonomous systems thanks to recent development in interactive algorithms that address covariate shift and compounding errors induced by traditional approaches like behavior cloning. However, existing interactive imitation learning methods assume access to one perfect expert. Whereas in reality, it is more likely to have multiple imperfect experts instead. In this paper, we propose MEGA-DAgger, a new DAgger variant that is suitable for interactive learning with multiple imperfect experts. First, unsafe demonstrations are filtered while aggregating the training data, so the imperfect demonstrations have little influence when training the novice policy. Next, experts are evaluated and compared on scenarios-specific metrics to resolve the conflicted labels among experts. Through experiments in autonomous racing scenarios, we demonstrate that policy learned using MEGA-DAgger can outperform both experts and policies learned using the state-of-the-art interactive imitation learning algorithm. The supplementary video can be found at https://youtu.be/pYQiPSHk6dU.
翻译:由于最近开发了互动算法,以解决诸如行为克隆等传统方法引起的共变转移和复合错误,对各种自主系统广泛应用了模拟学习。然而,现有的互动模拟学习方法假定了一名完美的专家。在现实中,它更有可能有多重不完善的专家。在本文中,我们建议采用适合与多重不完善专家进行互动学习的新的Dagger变体MEGA-Dagger。首先,在合并培训数据的同时,对不安全的演示进行过滤,因此,不完善的演示在培训新政策时影响不大。接下来,对专家进行具体情景评估,比较解决专家之间相互冲突标签的参数。我们通过在自主竞赛情景中的实验,证明使用MEGA-Dagger所学的政策可以超越使用最先进的交互式模拟学习算法所学的专家和政策。补充视频可在https://youtu.be/pYQIPSHk6dU上找到。</s>