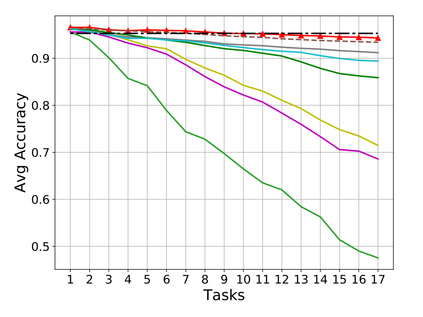
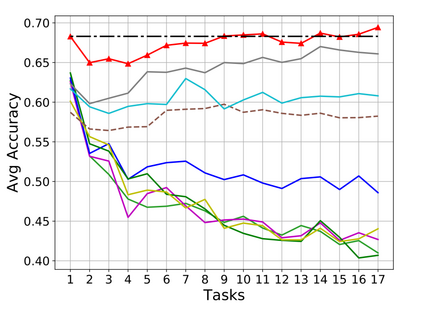
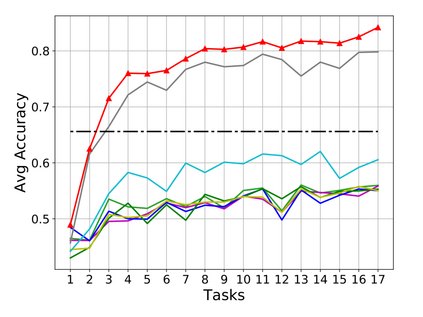
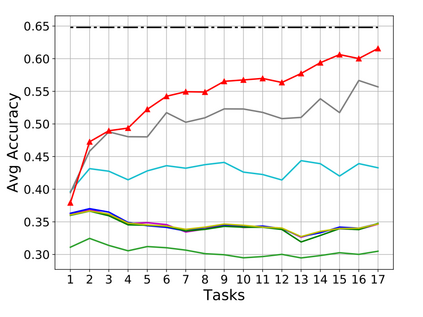
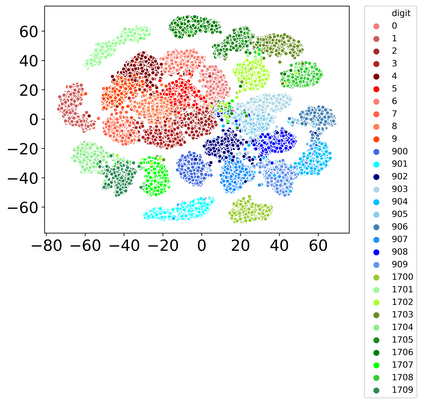
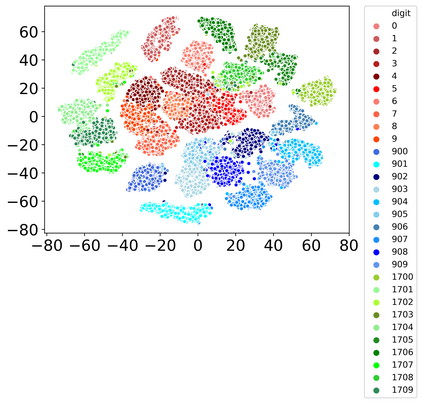
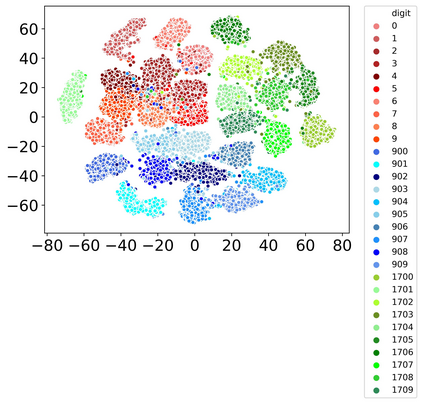
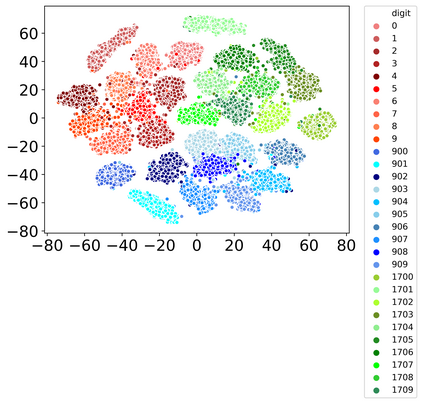
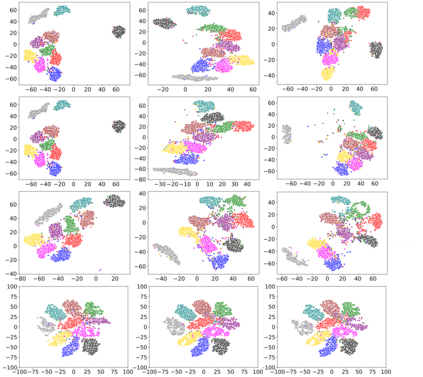
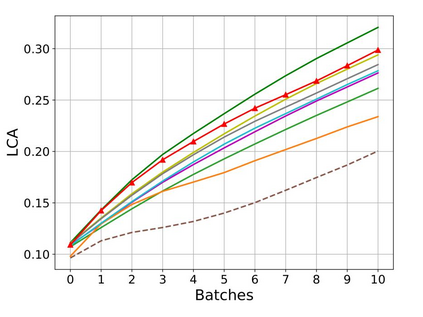
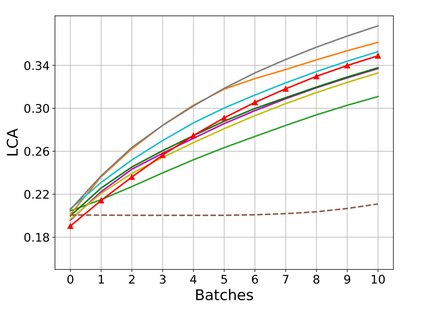
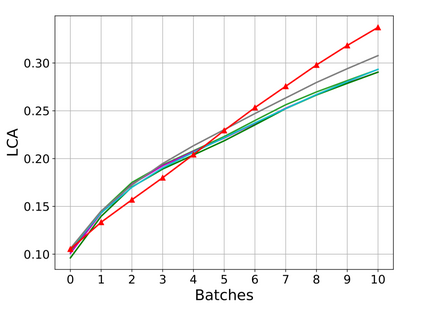
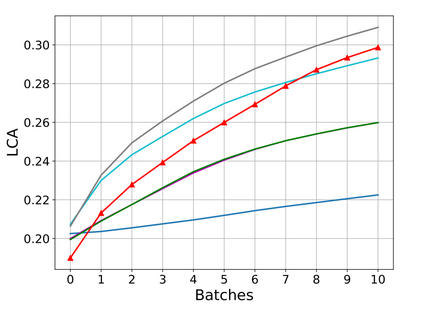
Rehearsal, seeking to remind the model by storing old knowledge in lifelong learning, is one of the most effective ways to mitigate catastrophic forgetting, i.e., biased forgetting of previous knowledge when moving to new tasks. However, the old tasks of the most previous rehearsal-based methods suffer from the unpredictable domain shift when training the new task. This is because these methods always ignore two significant factors. First, the Data Imbalance between the new task and old tasks that makes the domain of old tasks prone to shift. Second, the Task Isolation among all tasks will make the domain shift toward unpredictable directions; To address the unpredictable domain shift, in this paper, we propose Multi-Domain Multi-Task (MDMT) rehearsal to train the old tasks and new task parallelly and equally to break the isolation among tasks. Specifically, a two-level angular margin loss is proposed to encourage the intra-class/task compactness and inter-class/task discrepancy, which keeps the model from domain chaos. In addition, to further address domain shift of the old tasks, we propose an optional episodic distillation loss on the memory to anchor the knowledge for each old task. Experiments on benchmark datasets validate the proposed approach can effectively mitigate the unpredictable domain shift.
翻译:重新演练,试图通过将旧知识储存在终身学习中来提醒模型,以提醒模型,这是减轻灾难性遗忘的最有效方法之一,即,在转向新任务时有偏向地忘记先前的知识。然而,以前以彩排为基础的方法的旧任务在培训新任务时会受到无法预测的域变换的影响。这是因为这些方法总是忽略两个重要因素。首先,新任务和旧任务之间的数据平衡使旧任务领域容易转移。第二,任务隔开将使域向无法预测的方向转移;第二,所有任务之间的分离将使域向无法预测的方向转移;为了解决无法预测的域变,在本文件中,我们提议多面多面形多面图(MDMMT)排练,以同时和同样地训练旧任务和新任务,打破任务之间的隔绝。具体地说,提出两个层次的角差值损失,鼓励级内/塔克紧紧紧紧紧紧和级/塔克任务领域之间的差异,使模型远离区域混乱。此外,为了进一步解决旧任务的域变换,我们提议在记忆中选择的缩缩略。