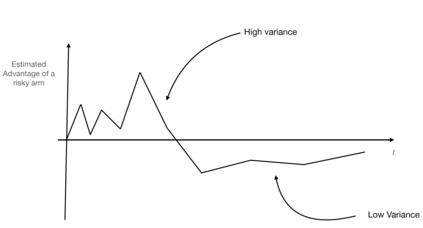
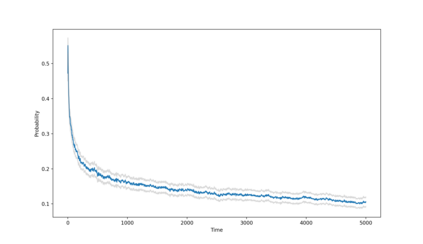
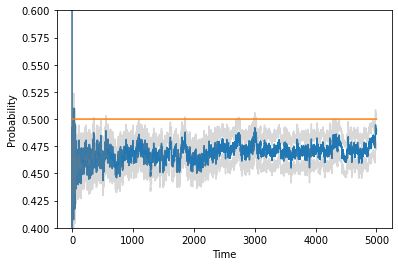
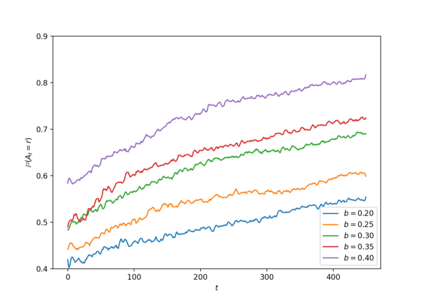
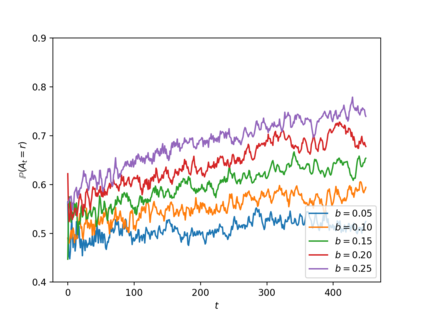
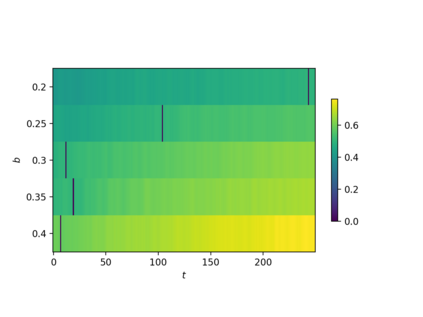
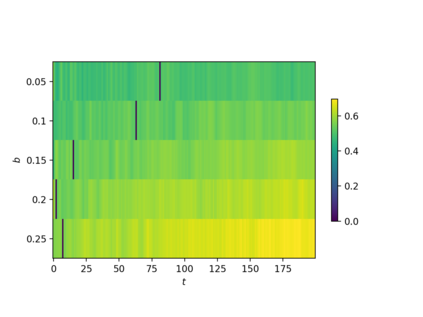
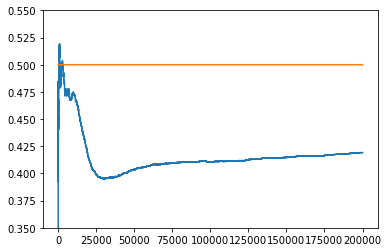
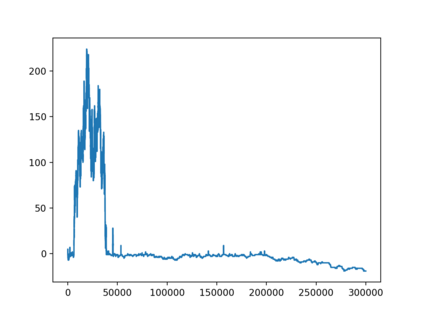
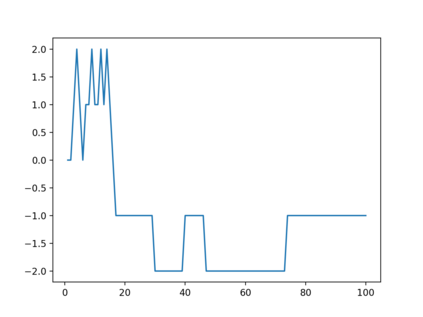
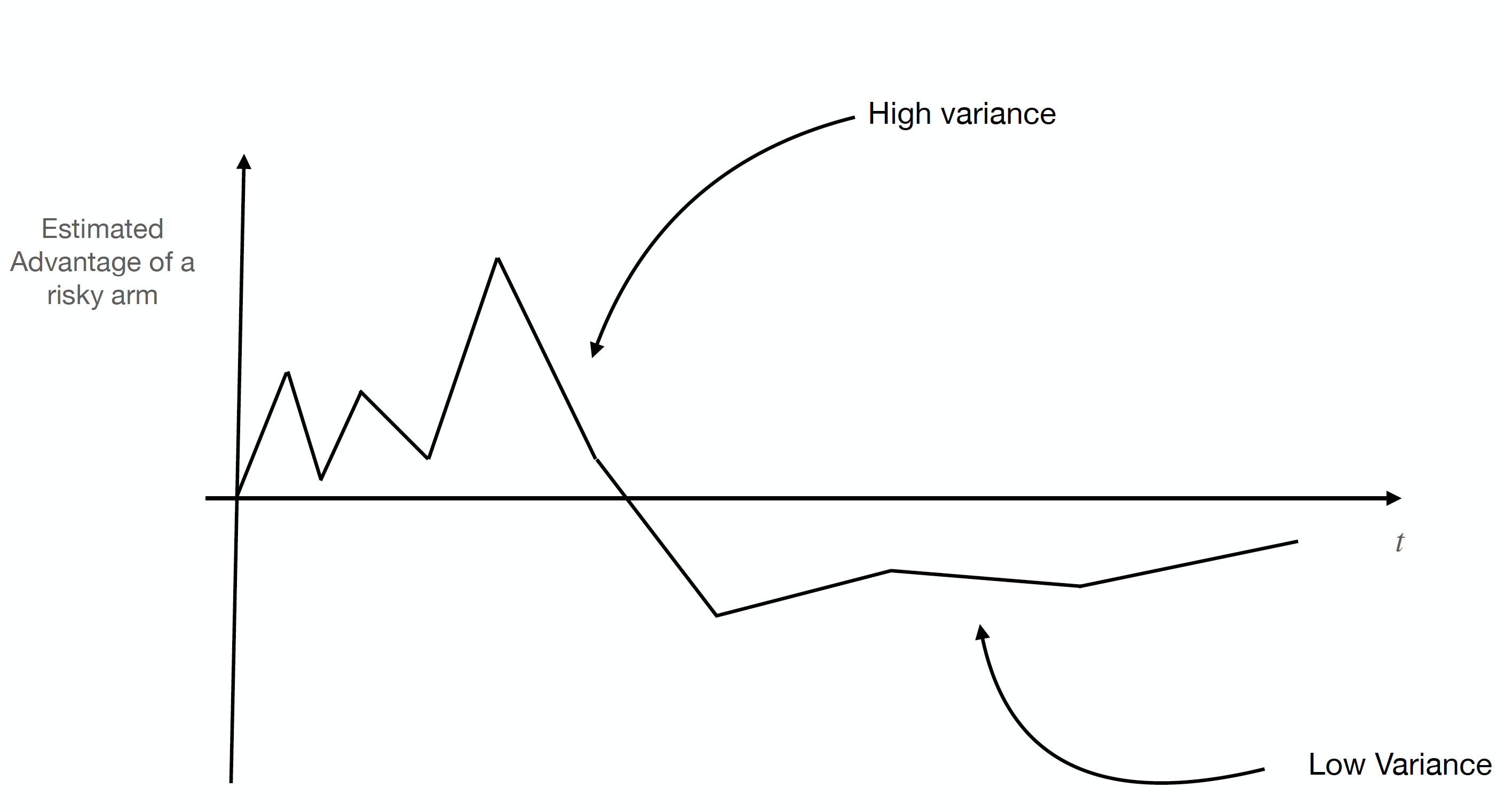
Consider online learning algorithms that simultaneously make decisions and learn from feedback. Such algorithms are widely deployed in recommendation systems for products and digital content. This article exhibits a bias of online learning algorithms towards less risky alternatives, and how it shapes demand on recommendation systems. First, we consider $k$-armed bandits. We prove that $\varepsilon$-Greedy chooses a riskless arm over a risky arm of equal expected reward with probability arbitrarily close to one. This is a consequence of undersampling of arms with bad reward estimates. Through experiments, we show that other online learning algorithms exhibit risk aversion as well. In a recommendation system environment we show that content that yields less noisy reward from users is favored by the algorithm. Combined with equilibrium forces driving strategic content creators towards content of similar expected quality, the advantage for content that is not necessarily better, just less volatile, is exaggerated.
翻译:考虑同时作出决定并从反馈中学习的在线学习算法。 这种算法被广泛用于产品和数字内容的建议系统。 文章展示了在线学习算法偏向于风险较低的替代方法, 以及它如何影响对建议系统的需求。 首先, 我们考虑的是手持$k$的土匪。 我们证明$varepsilon-Greedy 选择了无风险的手臂, 而不是风险的手臂, 并且可能任意地接近于一个。 这是低估武器与不良报酬估计的抽样的结果。 我们通过实验, 显示其他在线学习算法也表现出风险反向。 在推荐系统环境中, 我们展示了从用户获得的不那么吵闹的奖励的内容受到算法的青睐。 与均衡驱动战略内容创造者实现类似预期质量内容的驱动力相结合, 对不一定更好、只是不太不稳定的内容的优势被夸大。