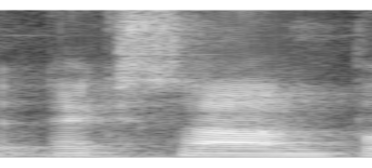
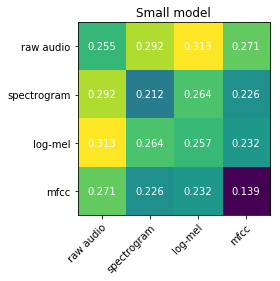
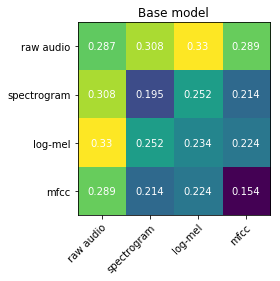
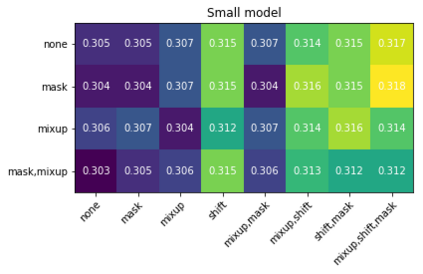
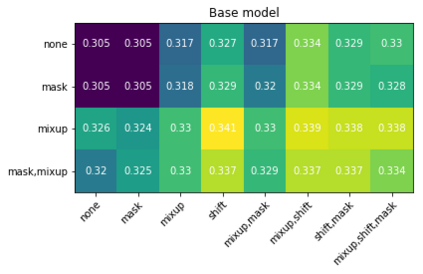
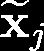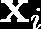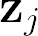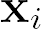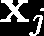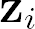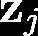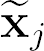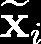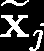Recent advances suggest the advantage of multi-modal training in comparison with single-modal methods. In contrast to this view, in our work we find that similar gain can be obtained from training with different formats of a single modality. In particular, we investigate the use of the contrastive learning framework to learn audio representations by maximizing the agreement between the raw audio and its spectral representation. We find a significant gain using this multi-format strategy against the single-format counterparts. Moreover, on the downstream AudioSet and ESC-50 classification task, our audio-only approach achieves new state-of-the-art results with a mean average precision of 0.376 and an accuracy of 90.5%, respectively.
翻译:最近的进展表明,与单一模式方法相比,多模式培训具有优势。与此相反,我们在工作中发现,采用不同模式的单一模式培训也能带来类似的收益。特别是,我们调查了使用对比式学习框架学习音频表现的方式,最大限度地实现原始音频及其光谱表达方式之间的一致。我们发现,使用这种多格式战略来对付单一格式对应方有很大的收益。此外,在下游音频Set和ESC-50分类任务方面,我们只使用音频方法取得了新的最新成果,平均平均精确度分别为0.376和90.5%。