
主题: Representations for Stable Off-Policy Reinforcement Learning
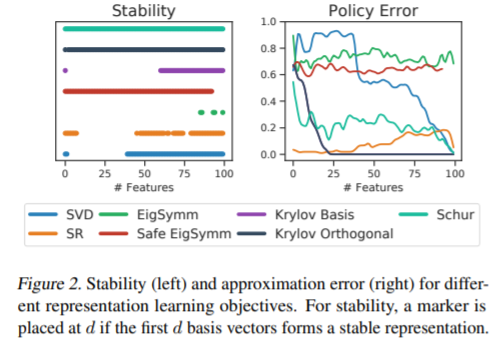
摘要: 具有函数逼近的强化学习可能不稳定,甚至会产生分歧,尤其是与非策略学习和Bellman更新结合使用时。在深度强化学习中,这些问题已通过调整和规范化表示形式(特别是辅助任务)以经验方式得到处理。这表明表示学习可以提供一种保证稳定性的方法。在本文中,我们正式表明,即使在学习非策略时,确实存在非平凡的状态表示形式,规范的TD算法是稳定的。我们沿着三个轴分析基于策略过渡矩阵(例如原型值函数)的表示学习方案:逼近误差,稳定性和易于估计性。在最一般的情况下,我们表明Schur基提供了收敛性保证,但是很难从样本中进行估计。对于固定的奖励函数,我们发现相应Krylov子空间的正交基础是更好的选择。我们通过经验证明,可以使用随机梯度下降学习这些稳定的表示,从而为使用深度网络进行表示学习的改进技术打开了大门。
成为VIP会员查看完整内容
相关内容
专知会员服务
41+阅读 · 2020年4月11日


相关VIP内容
专知会员服务
41+阅读 · 2020年4月11日
相关资讯
相关论文