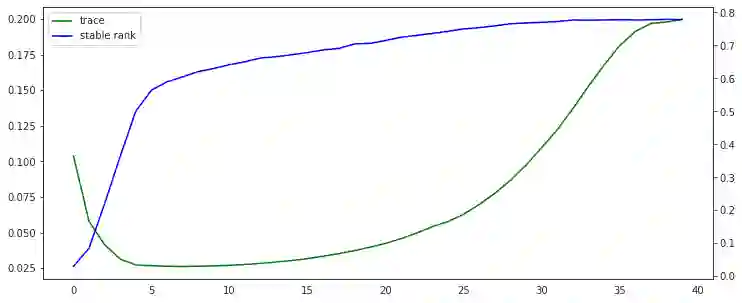
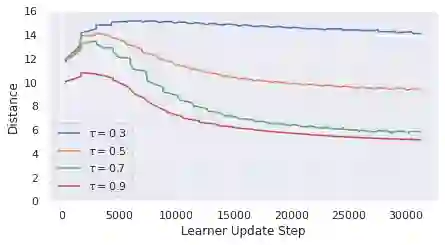
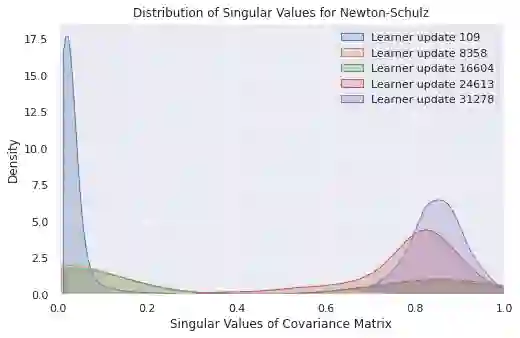
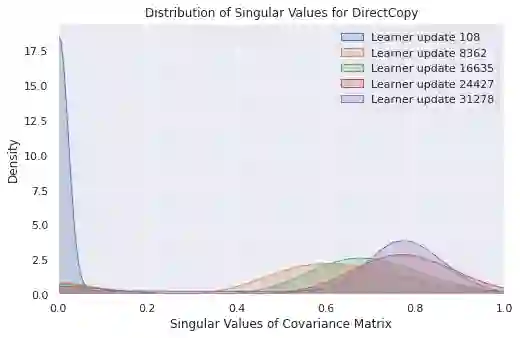
Self-predictive unsupervised learning methods such as BYOL or SimSiam have shown impressive results, and counter-intuitively, do not collapse to trivial representations. In this work, we aim at exploring the simplest possible mathematical arguments towards explaining the underlying mechanisms behind self-predictive unsupervised learning. We start with the observation that those methods crucially rely on the presence of a predictor network (and stop-gradient). With simple linear algebra, we show that when using a linear predictor, the optimal predictor is close to an orthogonal projection, and propose a general framework based on orthonormalization that enables to interpret and give intuition on why BYOL works. In addition, this framework demonstrates the crucial role of the exponential moving average and stop-gradient operator in BYOL as an efficient orthonormalization mechanism. We use these insights to propose four new \emph{closed-form predictor} variants of BYOL to support our analysis. Our closed-form predictors outperform standard linear trainable predictor BYOL at $100$ and $300$ epochs (top-$1$ linear accuracy on ImageNet).
翻译:BYOL 或 SimSiam 等自我预测的不受监督的学习方法显示出令人印象深刻的结果,反直觉地显示,不会崩溃为微不足道的表示。在这项工作中,我们的目标是探索最简单的数学参数,以解释自我预测的、不受监督的学习背后的基本机制。我们首先观察,这些方法关键地依赖一个预测者网络的存在(和停止-梯度)。用简单的线性代数,我们显示,在使用线性预测器时,最佳预测器接近于一个正方形预测,并提议一个基于正态的通用框架,以便能够解释和直视BYOL工作的原因。此外,这个框架展示了BYOL指数移动平均和中位操作者作为高效或正态机制的关键作用。我们用这些洞察力来提出四种新的BYOL的emph{封闭式预测器变式来支持我们的分析。我们的封闭式预测器超过标准的直线性预测器,其值为100美元和300美元远方美元。