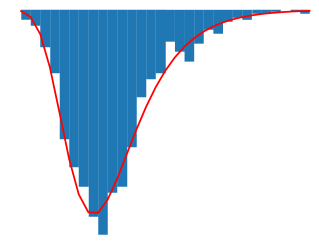
Deep neural networks have achieved remarkable success in computer vision tasks. Existing neural networks mainly operate in the spatial domain with fixed input sizes. For practical applications, images are usually large and have to be downsampled to the predetermined input size of neural networks. Even though the downsampling operations reduce computation and the required communication bandwidth, it removes both redundant and salient information obliviously, which results in accuracy degradation. Inspired by digital signal processing theories, we analyze the spectral bias from the frequency perspective and propose a learning-based frequency selection method to identify the trivial frequency components which can be removed without accuracy loss. The proposed method of learning in the frequency domain leverages identical structures of the well-known neural networks, such as ResNet-50, MobileNetV2, and Mask R-CNN, while accepting the frequency-domain information as the input. Experiment results show that learning in the frequency domain with static channel selection can achieve higher accuracy than the conventional spatial downsampling approach and meanwhile further reduce the input data size. Specifically for ImageNet classification with the same input size, the proposed method achieves 1.41% and 0.66% top-1 accuracy improvements on ResNet-50 and MobileNetV2, respectively. Even with half input size, the proposed method still improves the top-1 accuracy on ResNet-50 by 1%. In addition, we observe a 0.8% average precision improvement on Mask R-CNN for instance segmentation on the COCO dataset.
翻译:深心神经网络在计算机视觉任务中取得了显著的成功。 现有的神经网络主要在空间领域运行,具有固定的输入大小。 在实际应用中,图像通常大,必须缩小于神经网络的预定输入大小。 尽管下下取样操作减少了计算和所需的通信带宽,但它会明显地消除冗余和突出的信息,从而导致精确度下降。 在数字信号处理理论的启发下,我们从频率角度分析光谱偏差,并提议基于学习的频率选择方法,以确定可以在不准确损失的情况下删除的微小频率组件。 拟议的频域网络学习方法利用众所周知的神经网络的相同结构,如ResNet-50、 MobileNetV2和Mack R-CNN,同时接受作为输入的频域网信息。 实验结果显示,通过静态频道选择在频率域的学习可以比传统的空间下取样方法更精确度更高,同时进一步减少输入数据大小。 在相同的输入实例分类中,提议的频率域域网学习方法将达到1.41% 和0.66% 移动网络的高级精确度改进,在SR- AS- AS- AS- hal- hold AS- hill AS- hill 上, AS- AS- hill AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- 0. 1 AS- AS- AS- AS- AS- AS- AS- AL- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AL- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS- AS