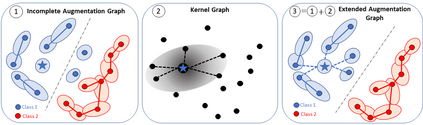
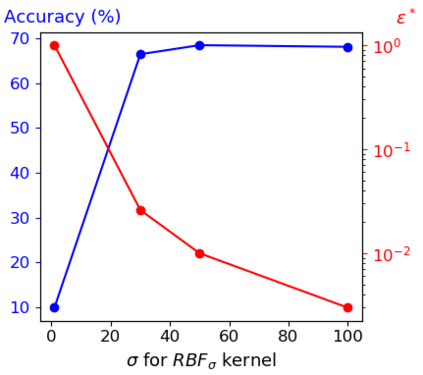
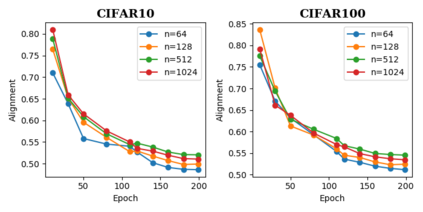
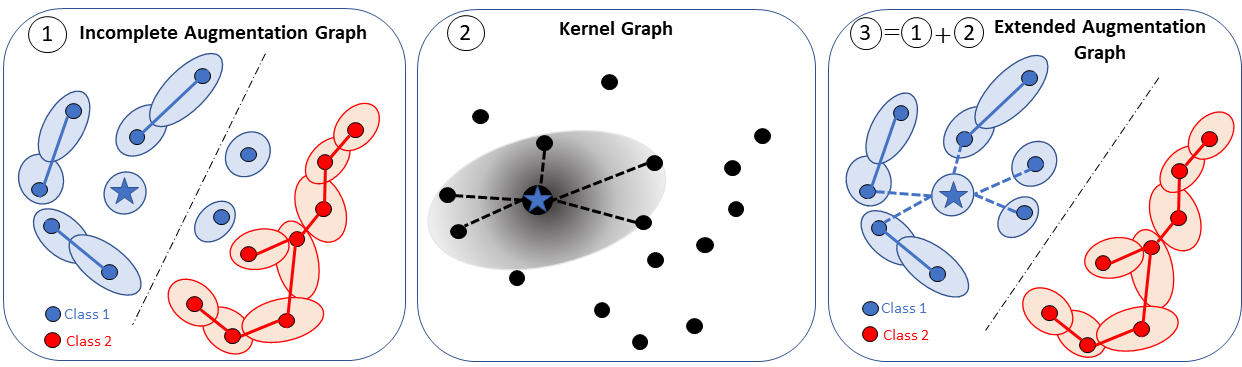
Data augmentation is a crucial component in unsupervised contrastive learning (CL). It determines how positive samples are defined and, ultimately, the quality of the representation. While efficient augmentations have been found for standard vision datasets, such as ImageNet, it is still an open problem in other applications, such as medical imaging, or in datasets with easy-to-learn but irrelevant imaging features. In this work, we propose a new way to define positive samples using kernel theory along with a novel loss called decoupled uniformity. We propose to integrate prior information, learnt from generative models or given as auxiliary attributes, into contrastive learning, to make it less dependent on data augmentation. We draw a connection between contrastive learning and the conditional mean embedding theory to derive tight bounds on the downstream classification loss. In an unsupervised setting, we empirically demonstrate that CL benefits from generative models, such as VAE and GAN, to less rely on data augmentations. We validate our framework on vision datasets including CIFAR10, CIFAR100, STL10 and ImageNet100 and a brain MRI dataset. In the weakly supervised setting, we demonstrate that our formulation provides state-of-the-art results.
翻译:数据增强是未经监督的对比性学习(CL)中的一个关键组成部分。 它决定了正样是如何定义的,最终是代表质量。 虽然在图像网络等标准视觉数据集中发现了高效增强,但在医学成像等其他应用中,或在容易读取但又不相关的成像特征的数据集中仍然是一个未解决的问题。 在这项工作中, 我们提出一种新的方法, 利用内核理论和新颖的分解性损失来定义正样。 我们提议将先前的信息, 从基因模型或作为辅助属性获得的信息, 纳入对比性学习, 以减少对数据增强的依赖。 我们把对比性学习与有条件的平均嵌入理论联系起来, 以获得下游分类损失的紧密界限。 在未经监督的环境下, 我们的经验证明, CL从基因化模型(如VAE和GAN)中受益, 较少依赖数据增强。 我们验证了我们的视觉数据集框架, 包括CIFAR10、 CIFAR100、 STL10 和图像Net100 以及大脑MRIS 和大脑MRISD 模型, 展示了薄弱的数据配置。