大型语言模型(LLM)赋能的知识图谱构建:综述
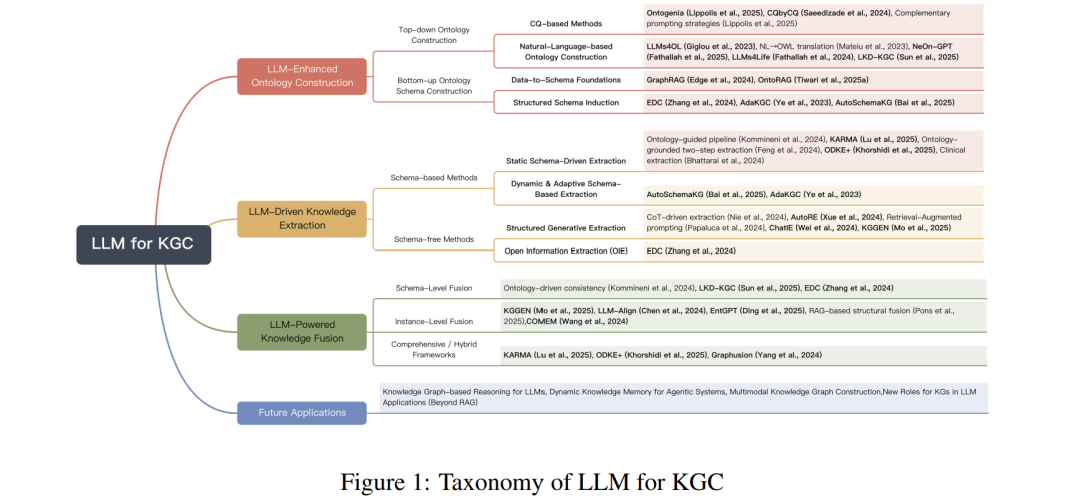
知识图谱(Knowledge Graph, KG)长期以来一直作为结构化知识表示与推理的核心基础设施。随着大型语言模型(Large Language Models, LLMs)的兴起,知识图谱的构建进入了一个全新的范式——从基于规则与统计的方法论管线,转向以语言驱动和生成式框架为核心的模式。本文综述了LLM赋能的知识图谱构建的最新进展,系统分析了LLM如何重塑传统的三层构建流程:本体工程、知识抽取与知识融合。 我们首先回顾了传统知识图谱的方法体系,以奠定概念基础;随后从两个互补的视角系统梳理了新兴的LLM驱动方法:基于模式(schema-based)范式,强调结构化、规范化与一致性;以及无模式(schema-free)范式,突出灵活性、适应性与开放式发现。在每个阶段中,我们汇总了具有代表性的框架,剖析其技术机制,并指出存在的局限性。 最后,本文总结了关键趋势与未来研究方向,包括:面向LLM的基于知识图谱的推理、面向智能体系统的动态知识记忆,以及多模态知识图谱构建。通过这项系统性综述,我们旨在阐明LLM与知识图谱之间不断演化的交互关系,推动符号知识工程与神经语义理解的融合,迈向自适应、可解释且智能的知识系统发展。
1 引言
知识图谱(Knowledge Graph, KG)长期以来一直是结构化知识表示、集成与推理的基石。它为语义搜索、问答系统以及科学发现等广泛的智能应用提供了统一的语义基础。传统的知识图谱构建流程通常由三个主要组成部分构成:本体工程(ontology engineering)、知识抽取(knowledge extraction)和知识融合(knowledge fusion)。尽管这些方法在支持大规模知识组织方面取得了显著成功,但传统范式(如 Zhong 等,2023;Zhao 等,2024)仍然面临三大长期性挑战: (1) 可扩展性与数据稀疏性问题:基于规则或监督学习的系统往往难以跨领域泛化; (2) 专家依赖与刚性问题:模式与本体的设计严重依赖人工干预,缺乏自适应性; (3) 流程割裂与误差累积问题:构建各阶段的割裂处理容易导致误差逐步传递。 这些限制阻碍了自演化(self-evolving)、大规模与动态知识图谱的发展。 大型语言模型(Large Language Models, LLMs)的出现,为突破上述瓶颈带来了范式级变革。通过大规模预训练与涌现的泛化能力,LLMs 引入了三种关键机制: (1) 生成式知识建模(Generative Knowledge Modeling) —— 直接从非结构化文本中合成结构化表示; (2) 语义统一(Semantic Unification) —— 通过自然语言对齐整合异构知识源; (3) 指令驱动的协同(Instruction-driven Orchestration) —— 以提示(prompt)为基础协调复杂的知识图谱构建流程。 因此,LLMs 正在从传统的文本处理工具演化为能够无缝连接自然语言与结构化知识的认知引擎(cognitive engines)(如 Zhu 等,2024b;Zhang & Soh,2024)。这一演化标志着知识图谱构建从规则驱动、流程化体系向LLM驱动的统一与自适应框架的根本转变。在这一新范式下,知识获取、组织与推理被视为在生成式与自精化(self-refining)生态系统中相互依存的过程(Pan 等,2024)。 鉴于该领域的迅速发展,本文对LLM驱动的知识图谱构建进行了全面综述。我们系统回顾了涵盖本体工程、知识抽取与知识融合的最新研究成果,分析了新兴方法论范式,并总结了LLM与知识表示交叉领域的开放挑战与未来方向。 本文结构如下: * 第2节 介绍传统知识图谱构建的基础,包括LLM出现前的本体工程、知识抽取与知识融合技术; * 第3节 回顾LLM增强的本体构建方法,涵盖自上而下范式(LLM作为本体助手)与自下而上范式(KG服务于LLM); * 第4节 介绍LLM驱动的知识抽取,对比基于模式与无模式的方法论; * 第5节 讨论LLM赋能的知识融合,重点分析模式层、实例层及混合型框架; * 第6节 探讨未来研究方向,包括基于知识图谱的推理、智能体系统中的动态知识记忆,以及多模态知识图谱构建。