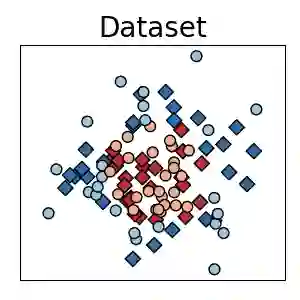
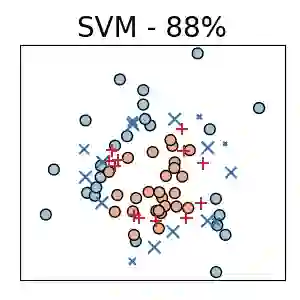
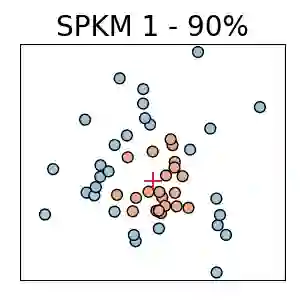
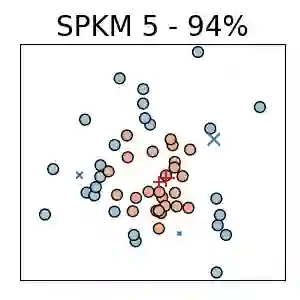
Traditionally, kernel methods rely on the representer theorem which states that the solution to a learning problem is obtained as a linear combination of the data mapped into the reproducing kernel Hilbert space (RKHS). While elegant from theoretical point of view, the theorem is prohibitive for algorithms' scalability to large datasets, and the interpretability of the learned function. In this paper, instead of using the traditional representer theorem, we propose to search for a solution in RKHS that has a pre-image decomposition in the original data space, where the elements don't necessarily correspond to the elements in the training set. Our gradient-based optimisation method then hinges on optimising over possibly sparse elements in the input space, and enables us to obtain a kernel-based model with both primal and dual sparsity. We give theoretical justification on the proposed method's generalization ability via a Rademacher bound. Our experiments demonstrate a better scalability and interpretability with accuracy on par with the traditional kernel-based models.
翻译:传统上, 内核方法依赖于代表理论, 该理论指出, 学习问题的解决方案是作为在复制内核 Hilbert 空间( RKHS) 中绘制的数据的线性组合获得的。 虽然从理论上看, 理论是优雅的, 但它对于算法向大型数据集的缩放性以及所学函数的可解释性来说是令人望而却步的。 在本文中, 我们不使用传统的代言理论, 我们提议在RKHS中寻找一个解决方案, 它将在原始数据空间中具有先成形分解的分解作用, 而在原始数据空间中, 元素不一定与培训数据集中的元素相对应。 我们的基于梯度的优化方法则取决于对输入空间中可能稀有的元素的优化, 并使我们能够获得一个具有原始和双重广度的内核模型。 我们对拟议方法通过Rademacher 捆绑的普及能力从理论上加以解释。 我们的实验显示, 与传统的内核模型的精确度更高和可解释性。