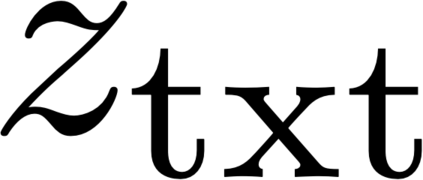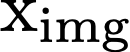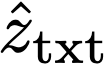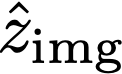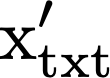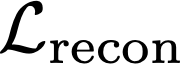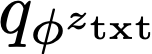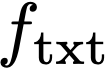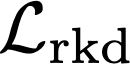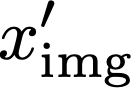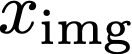We propose a text-to-image generation algorithm based on deep neural networks when text captions for images are unavailable during training. In this work, instead of simply generating pseudo-ground-truth sentences of training images using existing image captioning methods, we employ a pretrained CLIP model, which is capable of properly aligning embeddings of images and corresponding texts in a joint space and, consequently, works well on zero-shot recognition tasks. We optimize a text-to-image generation model by maximizing the data log-likelihood conditioned on pairs of image-text CLIP embeddings. To better align data in the two domains, we employ a principled way based on a variational inference, which efficiently estimates an approximate posterior of the hidden text embedding given an image and its CLIP feature. Experimental results validate that the proposed framework outperforms existing approaches by large margins under unsupervised and semi-supervised text-to-image generation settings.
翻译:我们提出了一种基于深度神经网络的文本图像生成算法,当训练期间图像的文本描述不可用时。在此工作中,我们不是简单地使用现有的图像字幕工具生成训练图像的伪真实句子,而是使用预训练的CLIP模型。该模型能够在联合空间中适当地对齐图像和相应文本的嵌入,并因此在零样本识别任务上表现出色。我们通过最大化基于图像文本CLIP嵌入对条件的数据对文本图像生成模型进行优化。为了更好地对齐两个领域中的数据,我们采用了基于变分推断的原则方法,它可以有效地估算出在给定图像及其CLIP特征的情况下的隐藏文本嵌入的近似后验分布。实验结果验证了在无监督和半监督文本图像生成设置下,所提出的框架优于现有方法很多。