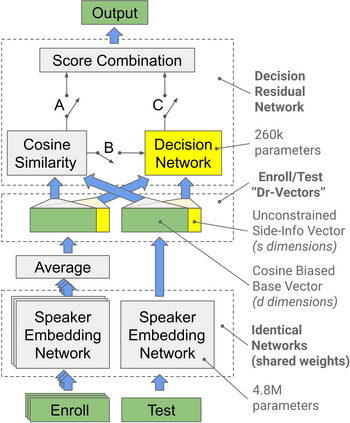
Many neural network speaker recognition systems model each speaker using a fixed-dimensional embedding vector. These embeddings are generally compared using either linear or 2nd-order scoring and, until recently, do not handle utterance-specific uncertainty. In this work we propose scoring these representations in a way that can capture uncertainty, enroll/test asymmetry and additional non-linear information. This is achieved by incorporating a 2nd-stage neural network (known as a decision network) as part of an end-to-end training regimen. In particular, we propose the concept of decision residual networks which involves the use of a compact decision network to leverage cosine scores and to model the residual signal that's needed. Additionally, we present a modification to the generalized end-to-end softmax loss function to better target the separation of same/different speaker scores. We observed significant performance gains for the two techniques.
翻译:在这项工作中,我们提议以能够捕捉不确定性、注册/测试不对称和额外非线性信息的方式评分这些表达方式。这是通过将第二阶段神经网络(称为决策网络)作为端到端培训制度的一部分而实现的。我们特别提出了决定剩余网络的概念,它涉及利用一个紧凑的决定网络来利用连线评分或第二顺序评分,并模拟所需的剩余信号。此外,我们提出了对一般端到端软负损失功能的修改,以更好地针对同一/不同发言者分数的分离。我们观察到两种技术的显著性能收益。