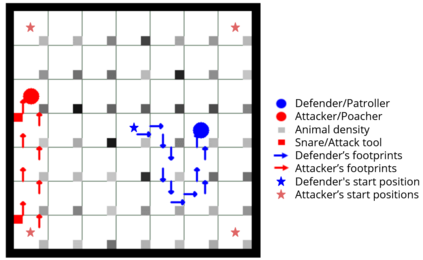
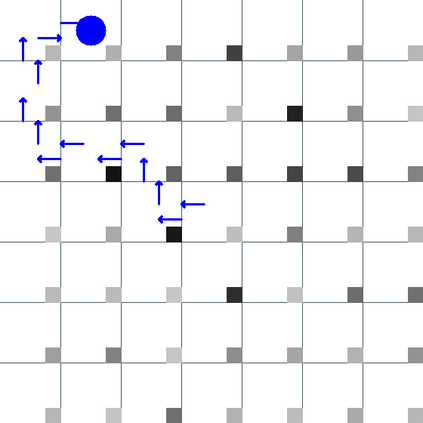
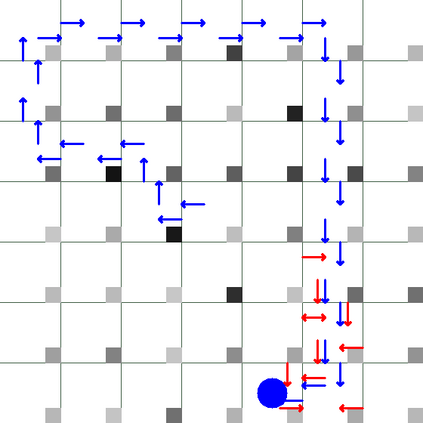
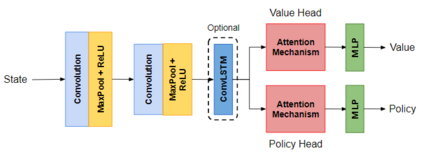
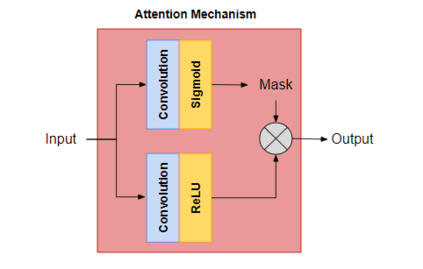
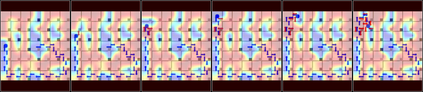
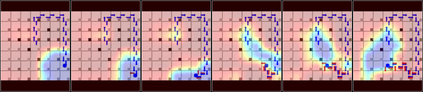
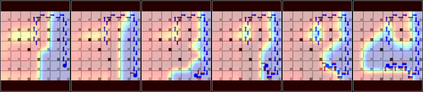
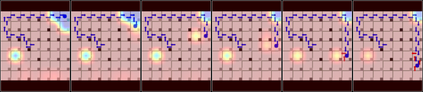
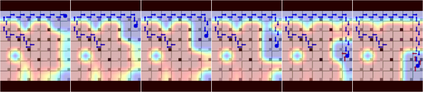
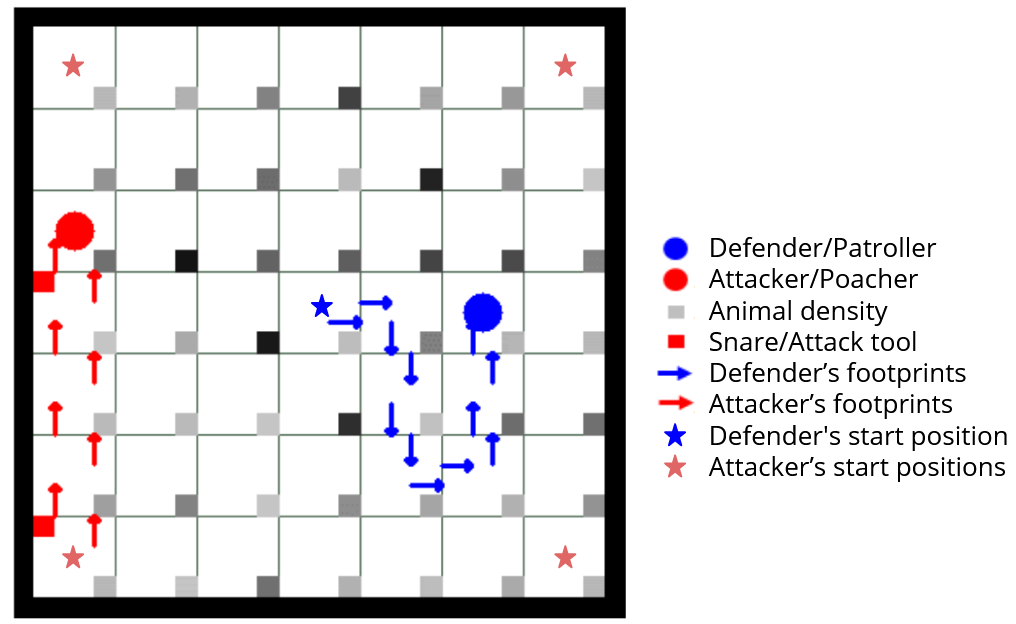
Green Security Games with real-time information (GSG-I) add the real-time information about the agents' movement to the typical GSG formulation. Prior works on GSG-I have used deep reinforcement learning (DRL) to learn the best policy for the agent in such an environment without any need to store the huge number of state representations for GSG-I. However, the decision-making process of DRL methods is largely opaque, which results in a lack of trust in their predictions. To tackle this issue, we present an interpretable DRL method for GSG-I that generates visualization to explain the decisions taken by the DRL algorithm. We also show that this approach performs better and works well with a simpler training regimen compared to the existing method.
翻译:绿色安全运动会的实时信息(GSG-I)将有关代理人运动的实时信息添加到典型的GSG-SG的配方中,GSG-I的先前工作曾使用深强化学习(DRL)来学习在这种环境中代理人的最佳政策,而无需为GSG-I储存大量的国家代表。然而,DRL方法的决策过程基本上不透明,导致对其预测缺乏信任。为解决这一问题,我们为GSG-I提出了一个可解释的DRL方法,生成可视化的方法,解释DRL算法做出的决定。我们还表明,这一方法运行良好,而且与现有方法相比,培训制度更为简单。