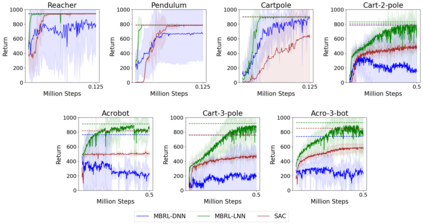
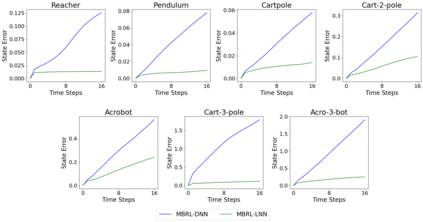
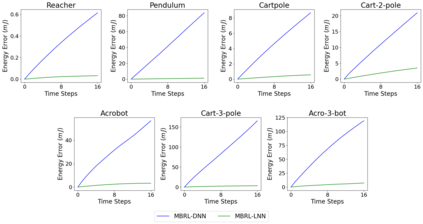
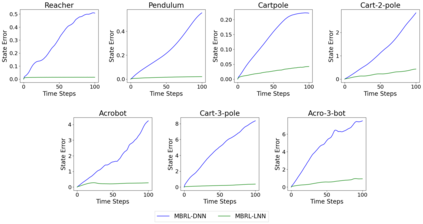
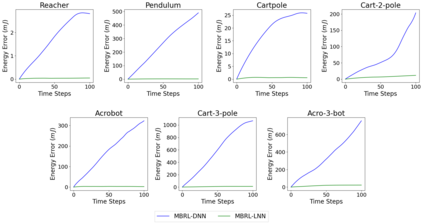
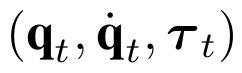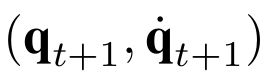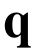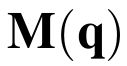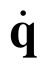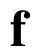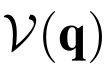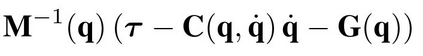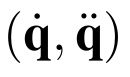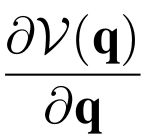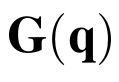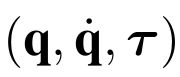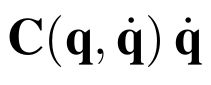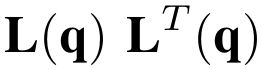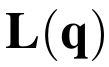One of the drawbacks of traditional reinforcement learning (RL) algorithms has been their poor sample efficiency. One approach to improve the sample efficiency is model-based RL. In our model-based RL algorithm, we learn a model of the environment, essentially its transition dynamics and reward function, use it to generate imaginary trajectories and backpropagate through them to update the policy, exploiting the differentiability of the model. Intuitively, learning more accurate models should lead to better performance. We focus on robotic systems undergoing rigid body motion without contacts. Recently, there has been growing interest in developing better deep neural network based dynamics models for physical systems, through better inductive biases. We compare two versions of our model-based RL algorithm, one which uses a standard deep neural network based dynamics model and the other which uses a much more accurate, physics-informed neural network based dynamics model. We show that, in model-based RL, model accuracy mainly matters in environments that are sensitive to initial conditions. In these environments, the physics-informed version of our algorithm achieves significantly better average-return and sample efficiency. In environments that are not sensitive to initial conditions, both versions of our algorithm achieve similar average-return, while the physics-informed version achieves better sample efficiency. We measure the sensitivity to initial conditions using the finite-time maximal Lyapunov exponent. We also show that, in challenging environments, where we need a lot of samples to learn, physics-informed model-based RL can achieve better average-return than state-of-the-art model-free RL algorithms such as Soft Actor-Critic, by generating accurate imaginary data.
翻译:传统的强化学习(RL)算法的一个缺点是其抽样效率低。改进抽样效率的一种方法是基于模型的RL。在我们基于模型的RL算法中,我们学习了一种环境模型,主要是其过渡动态和奖赏功能,利用它来产生想象的轨迹,并通过它们来产生假造的轨迹和反演算法,通过它们来更新政策,利用模型的不同性能。从直觉看,学习更准确的模型应该导致更好的性能。我们注重机器人系统,在没有接触的情况下,正在僵硬的体样样运动。最近,人们越来越有兴趣为物理系统开发更深的基于神经网络的动态模型。在基于模型的RL算法的模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型模型