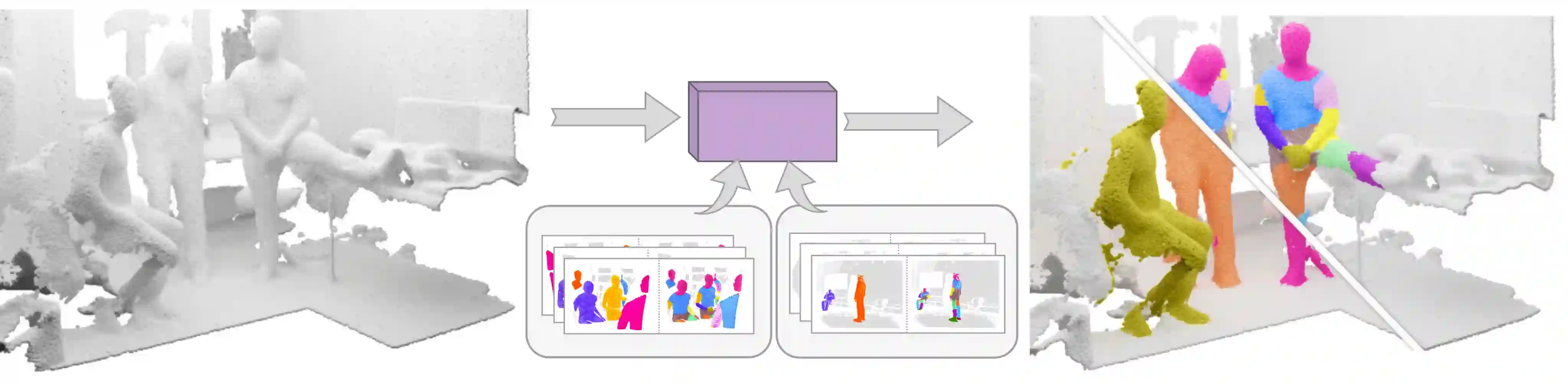
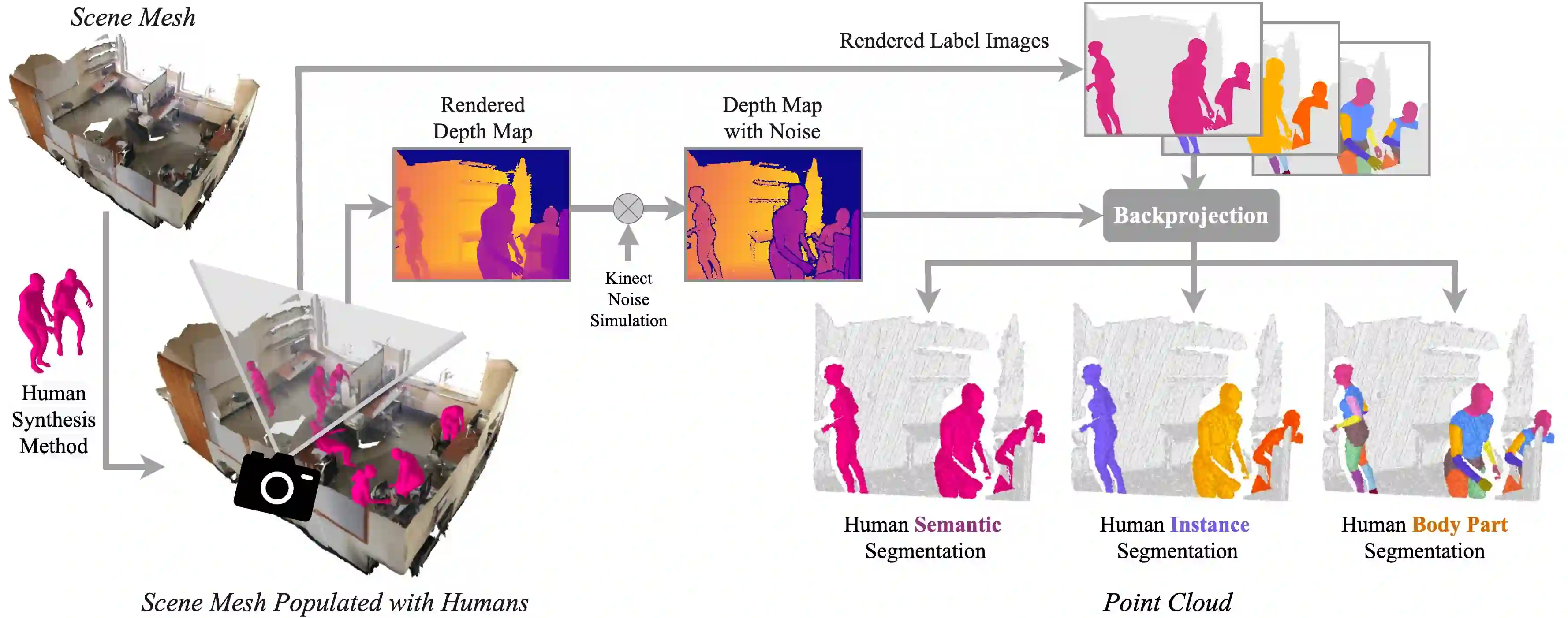
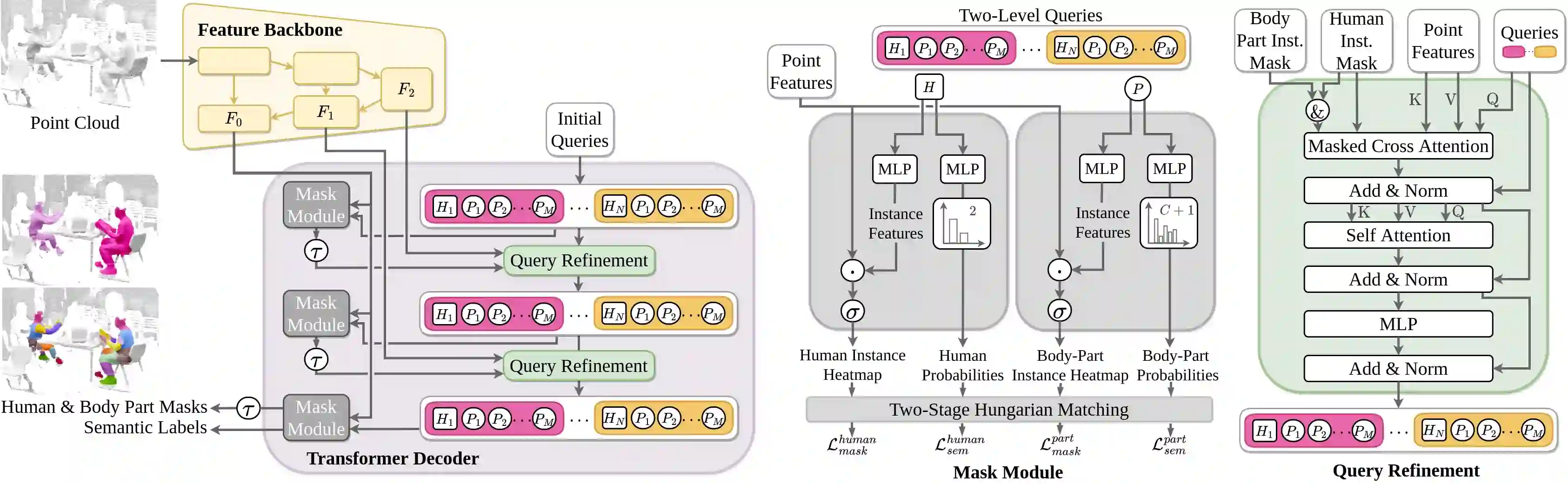
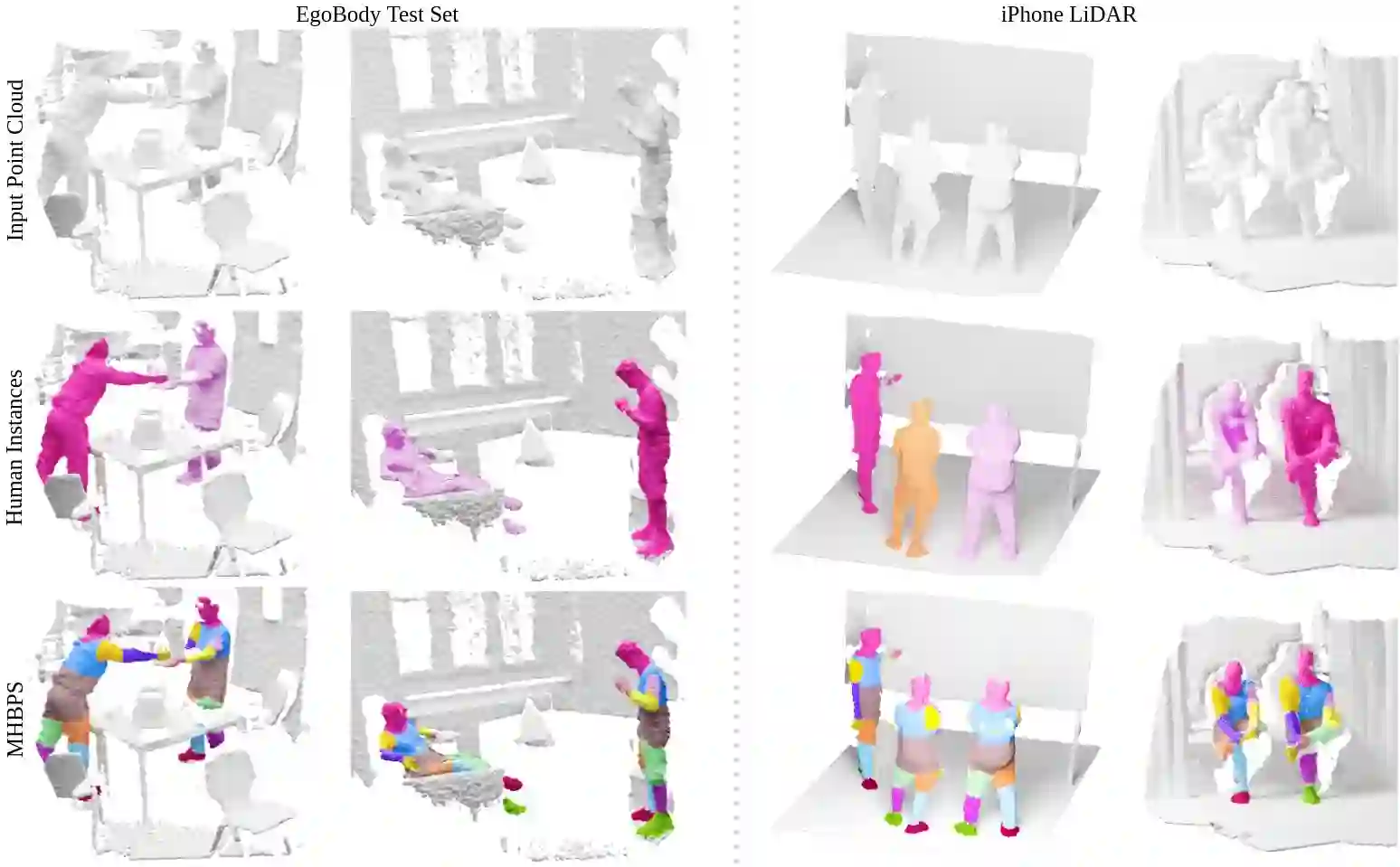
Segmenting humans in 3D indoor scenes has become increasingly important with the rise of human-centered robotics and AR/VR applications. In this direction, we explore the tasks of 3D human semantic-, instance- and multi-human body-part segmentation. Few works have attempted to directly segment humans in point clouds (or depth maps), which is largely due to the lack of training data on humans interacting with 3D scenes. We address this challenge and propose a framework for synthesizing virtual humans in realistic 3D scenes. Synthetic point cloud data is attractive since the domain gap between real and synthetic depth is small compared to images. Our analysis of different training schemes using a combination of synthetic and realistic data shows that synthetic data for pre-training improves performance in a wide variety of segmentation tasks and models. We further propose the first end-to-end model for 3D multi-human body-part segmentation, called Human3D, that performs all the above segmentation tasks in a unified manner. Remarkably, Human3D even outperforms previous task-specific state-of-the-art methods. Finally, we manually annotate humans in test scenes from EgoBody to compare the proposed training schemes and segmentation models.
翻译:随着以人为中心的机器人和AR/VR应用的上升,将人类分解到3D室内场面已变得日益重要。在这个方向上,我们探索3D人类语义、实例和多人身体部分分割的任务。很少有作品试图将人类直接分解成点云(或深度地图),这主要是因为缺乏与3D场面相互作用的人类培训数据。我们应对这一挑战,并提议一个框架,在现实的3D场面上合成虚拟人类。合成点云数据具有吸引力,因为实际和合成深度之间的域间差距小于图像。我们利用合成和现实数据对不同培训计划的分析表明,培训前的合成数据改进了各种分解任务和模型的性能。我们进一步提议了3D多人身体部分互动的第一个端对端模型,称为人类3D,以统一的方式执行所有以上分解任务。值得注意的是,人类3D甚至超越了以前任务特定状态与合成深度之间的距离。我们用合成和现实数据组合对不同培训计划的分析表明,培训前的合成数据改进了各种分解任务阶段和模型。最后,我们提议了从Egrodugaltotototoal-tradestration side cult化模型,我们建议了Ejodustrationaltaltaltaltaltaltaltaltraduction saldatedaldatedatedald speutds。