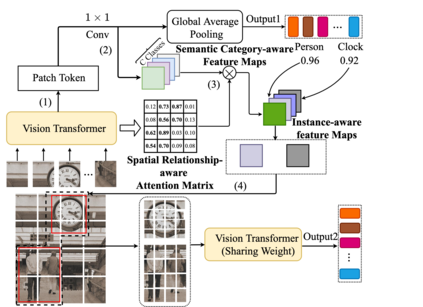
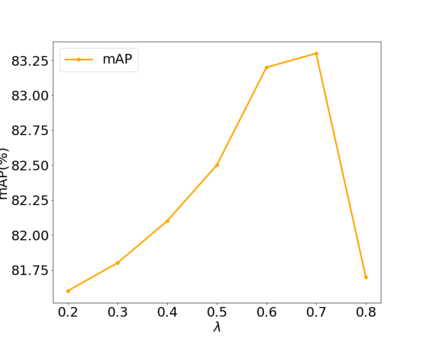
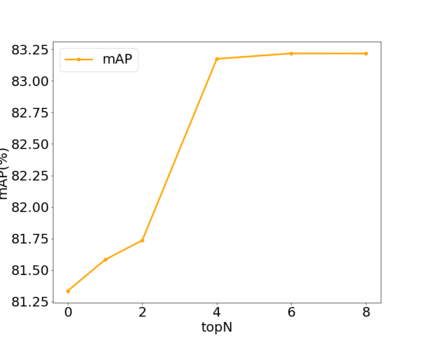
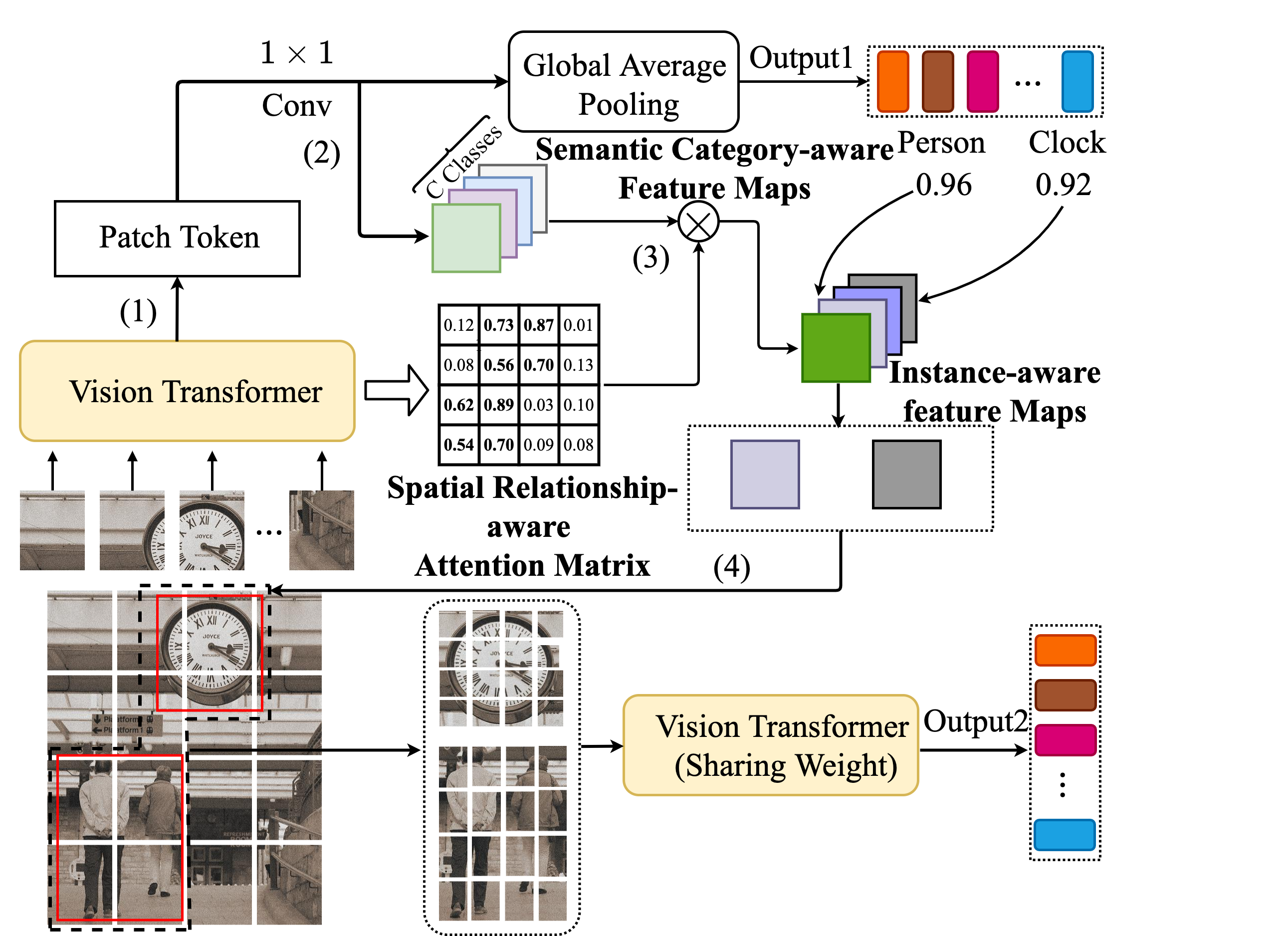
Previous works on multi-label image recognition (MLIR) usually use CNNs as a starting point for research. In this paper, we take pure Vision Transformer (ViT) as the research base and make full use of the advantages of Transformer with long-range dependency modeling to circumvent the disadvantages of CNNs limited to local receptive field. However, for multi-label images containing multiple objects from different categories, scales, and spatial relations, it is not optimal to use global information alone. Our goal is to leverage ViT's patch tokens and self-attention mechanism to mine rich instances in multi-label images, named diverse instance discovery (DiD). To this end, we propose a semantic category-aware module and a spatial relationship-aware module, respectively, and then combine the two by a re-constraint strategy to obtain instance-aware attention maps. Finally, we propose a weakly supervised object localization-based approach to extract multi-scale local features, to form a multi-view pipeline. Our method requires only weakly supervised information at the label level, no additional knowledge injection or other strongly supervised information is required. Experiments on three benchmark datasets show that our method significantly outperforms previous works and achieves state-of-the-art results under fair experimental comparisons.
翻译:多标签图像识别(MLIR)先前的多标签图像识别(MLIR)工作通常使用CNN(CNN)作为研究的起点。在本文中,我们把纯视野变异器(VIT)作为研究基地,充分利用长距离依赖模型变异器的优势,以规避仅局限于当地可接受域的CNN的劣势。然而,对于包含不同类别、尺度和空间关系等多个对象的多标签图像的多标签图像,单用全球信息是不理想的。我们的目标是利用VIT的补丁和自留机制来利用多标签级图像中的丰富实例,命名为不同实例发现(DID)。为此,我们建议分别使用一个具有长期依赖模型的语义类变异器模块和空间关系识别模块,然后通过重新控制战略将两者结合起来,以获取有实例可觉注意的地图。最后,我们建议采用一个薄弱的基于目标的本地定位的定位方法来提取多尺度的本地特征,形成多视角管道。我们的方法只需要在标签级别上进行薄弱的监管信息,不需要额外的知识注入,或者其它严格监督的信息。为此,我们需要在前三个基准状态下进行实验性比较。