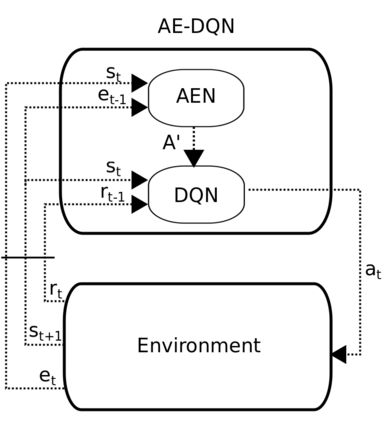
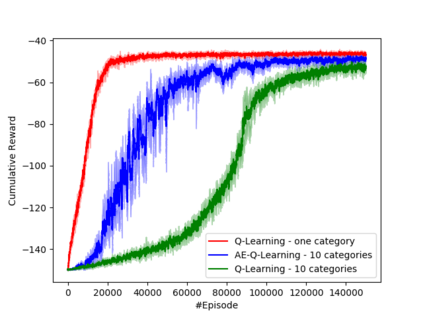
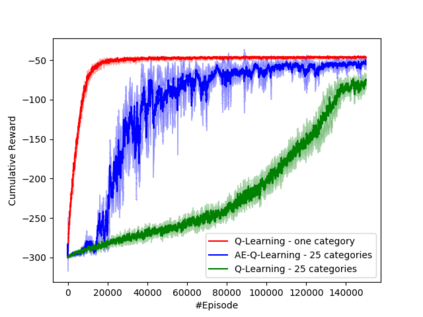
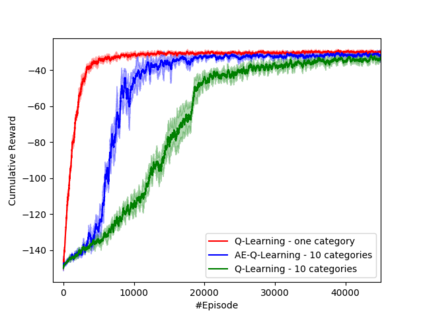
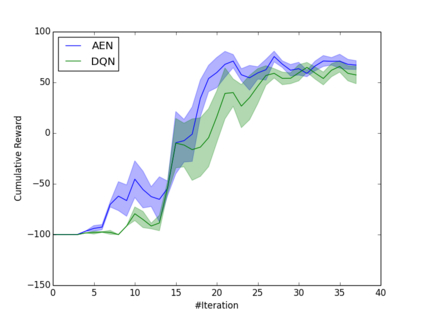
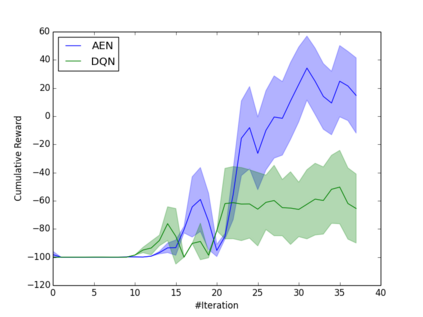
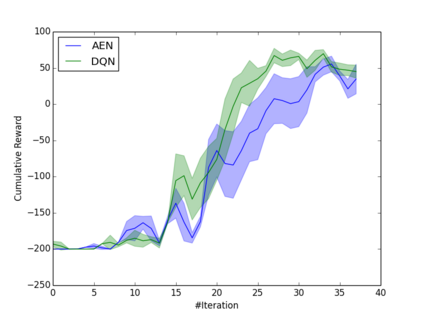
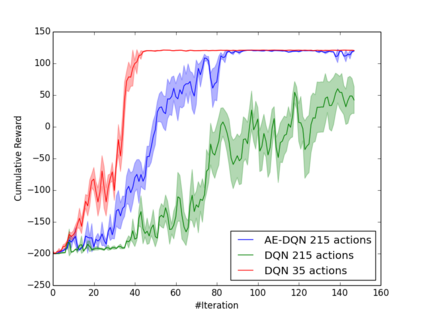
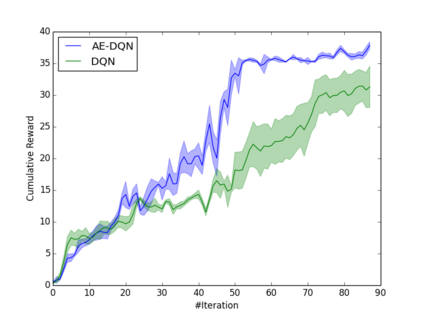
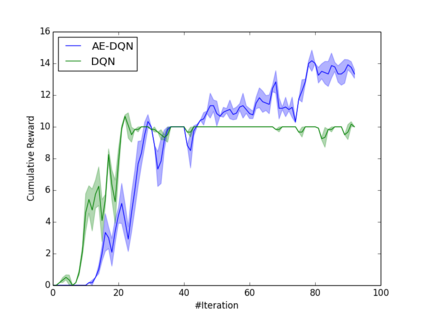
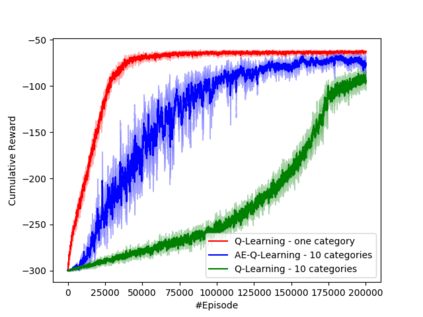
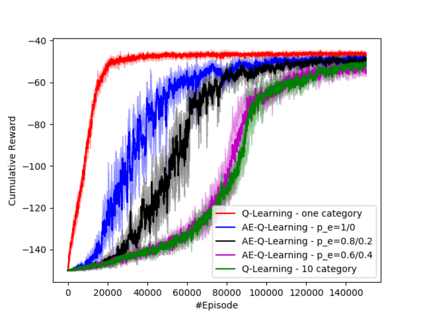
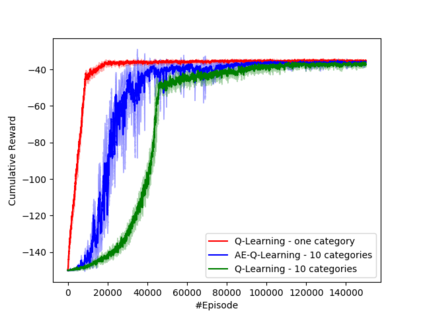
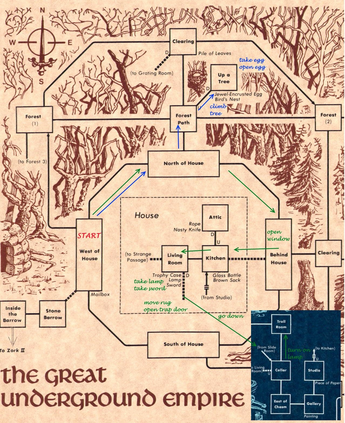
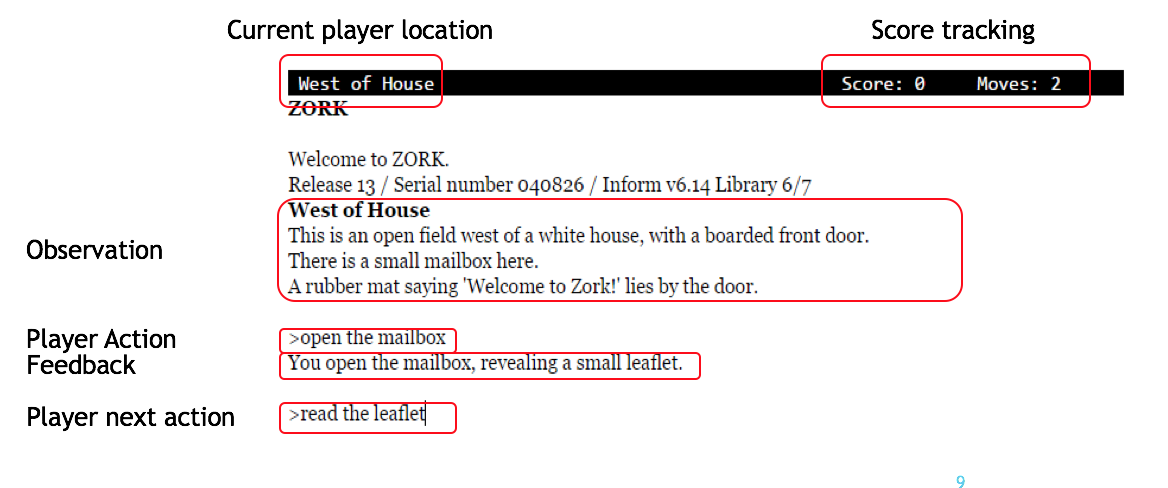
Learning how to act when there are many available actions in each state is a challenging task for Reinforcement Learning (RL) agents, especially when many of the actions are redundant or irrelevant. In such cases, it is sometimes easier to learn which actions not to take. In this work, we propose the Action-Elimination Deep Q-Network (AE-DQN) architecture that combines a Deep RL algorithm with an Action Elimination Network (AEN) that eliminates sub-optimal actions. The AEN is trained to predict invalid actions, supervised by an external elimination signal provided by the environment. Simulations demonstrate a considerable speedup and added robustness over vanilla DQN in text-based games with over a thousand discrete actions.
翻译:当每个州有许多可用的行动时,学习如何行动对于加强学习(RL)代理机构来说是一项艰巨的任务,特别是当许多行动是多余或无关紧要时。在这种情况下,有时更容易了解哪些行动不采取。在这项工作中,我们提议了“行动-消除深度Q-Network”(AE-DQN)架构,将深RL算法与消除亚优行动的消除行动网络(AEN)结合起来。AEN受过培训,在环境提供的外部消除信号监督下,预测无效行动。模拟显示,在文本游戏中,有一千多个独立的动作,比Vanilla DQN更加快速和有力。