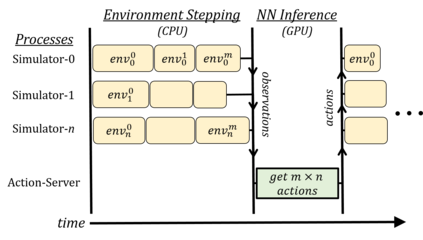
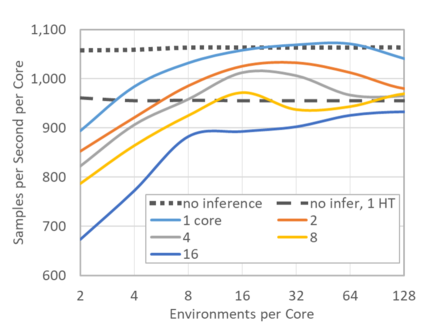
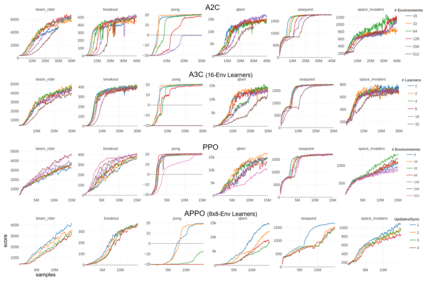
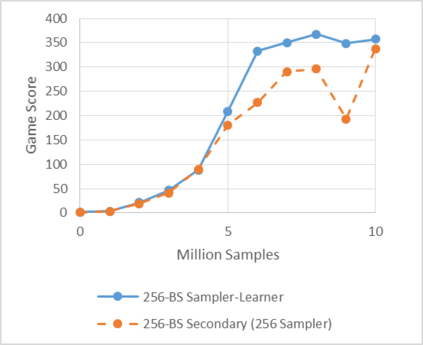
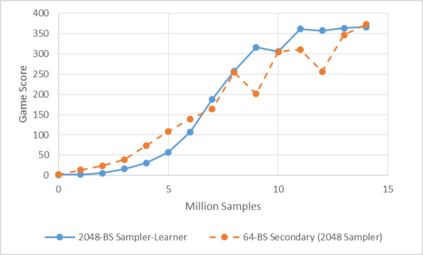
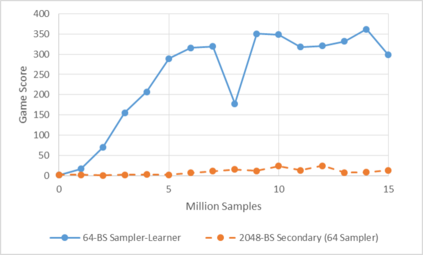
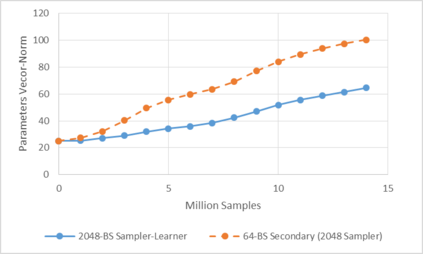
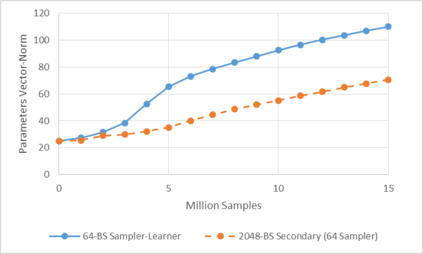
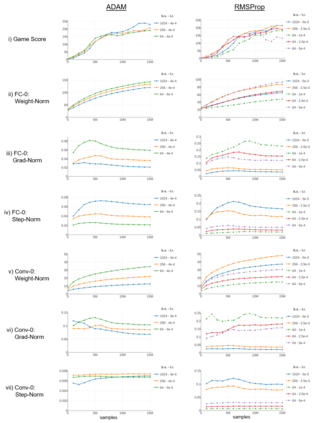
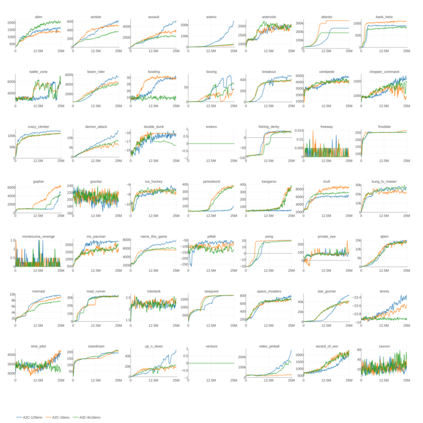
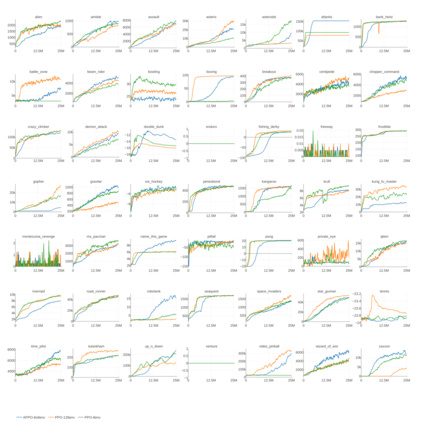
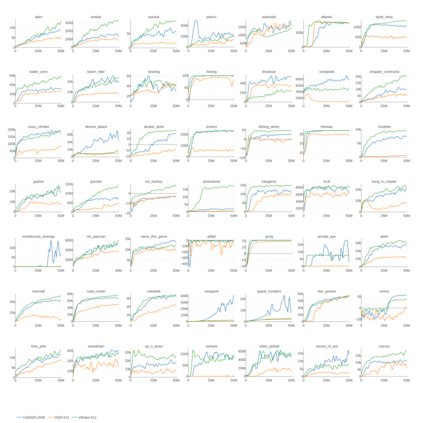
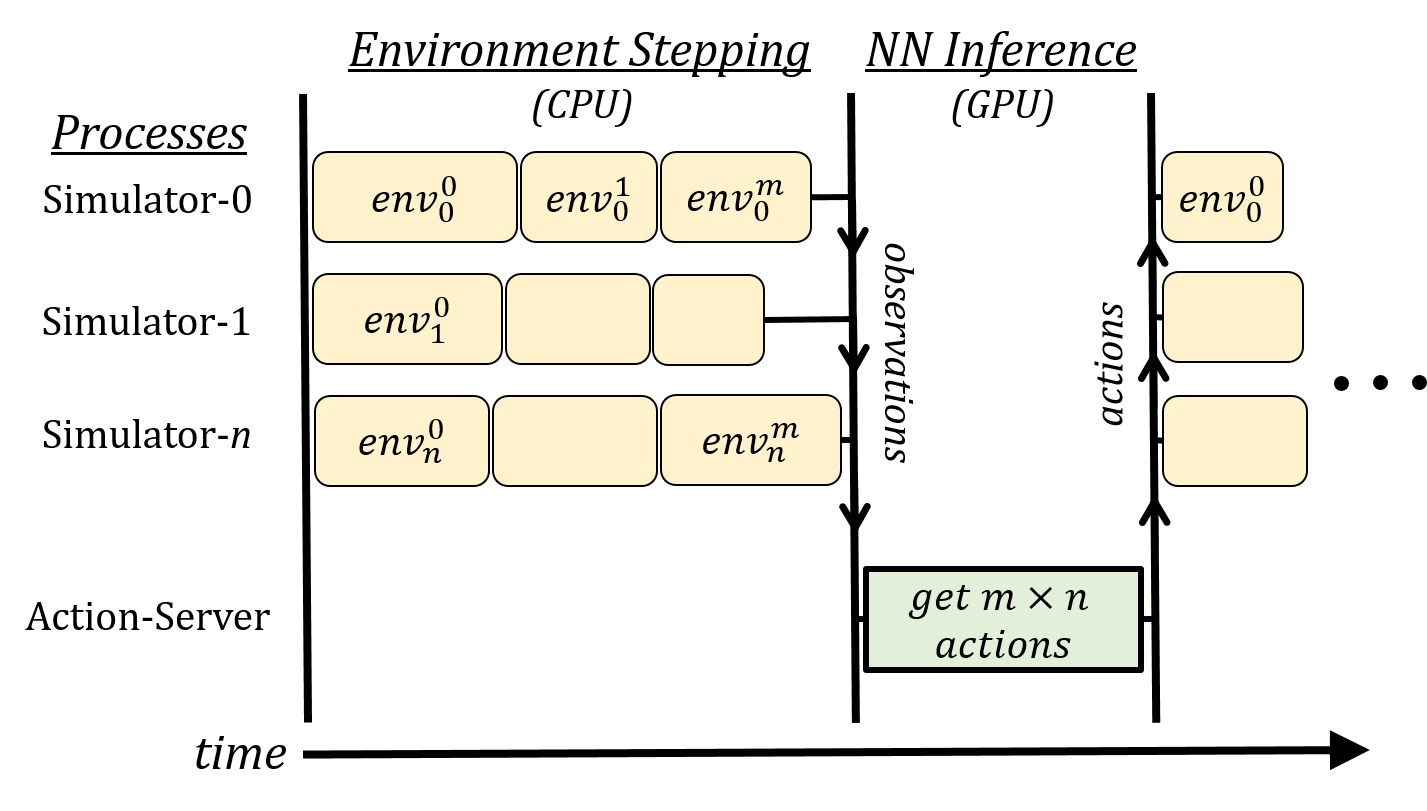
Deep reinforcement learning (RL) has achieved many recent successes, yet experiment turn-around time remains a key bottleneck in research and in practice. We investigate how to optimize existing deep RL algorithms for modern computers, specifically for a combination of CPUs and GPUs. We confirm that both policy gradient and Q-value learning algorithms can be adapted to learn using many parallel simulator instances. We further find it possible to train using batch sizes considerably larger than are standard, without negatively affecting sample complexity or final performance. We leverage these facts to build a unified framework for parallelization that dramatically hastens experiments in both classes of algorithm. All neural network computations use GPUs, accelerating both data collection and training. Our results include using an entire DGX-1 to learn successful strategies in Atari games in mere minutes, using both synchronous and asynchronous algorithms.
翻译:深入强化学习(RL)最近取得了许多成功,但实验周转时间仍然是研究和实践中的一个关键瓶颈。我们调查如何优化现代计算机的现有深度RL算法,特别是CPU和GPU的组合。我们确认,政策梯度和Q值学习算法都可以调整,以便使用许多平行模拟器来学习。我们进一步发现,使用批量尺寸比标准大得多的训练是可能的,但不会对样本复杂性或最终性能产生不利影响。我们利用这些事实来建立一个统一的平行框架,大大加快两种算法的实验。所有神经网络计算都使用GPU,加快数据收集和培训。我们的结果包括使用整个DGX-1在短短几分钟内学习阿塔里游戏的成功策略,同时使用同步和不同步的算法。