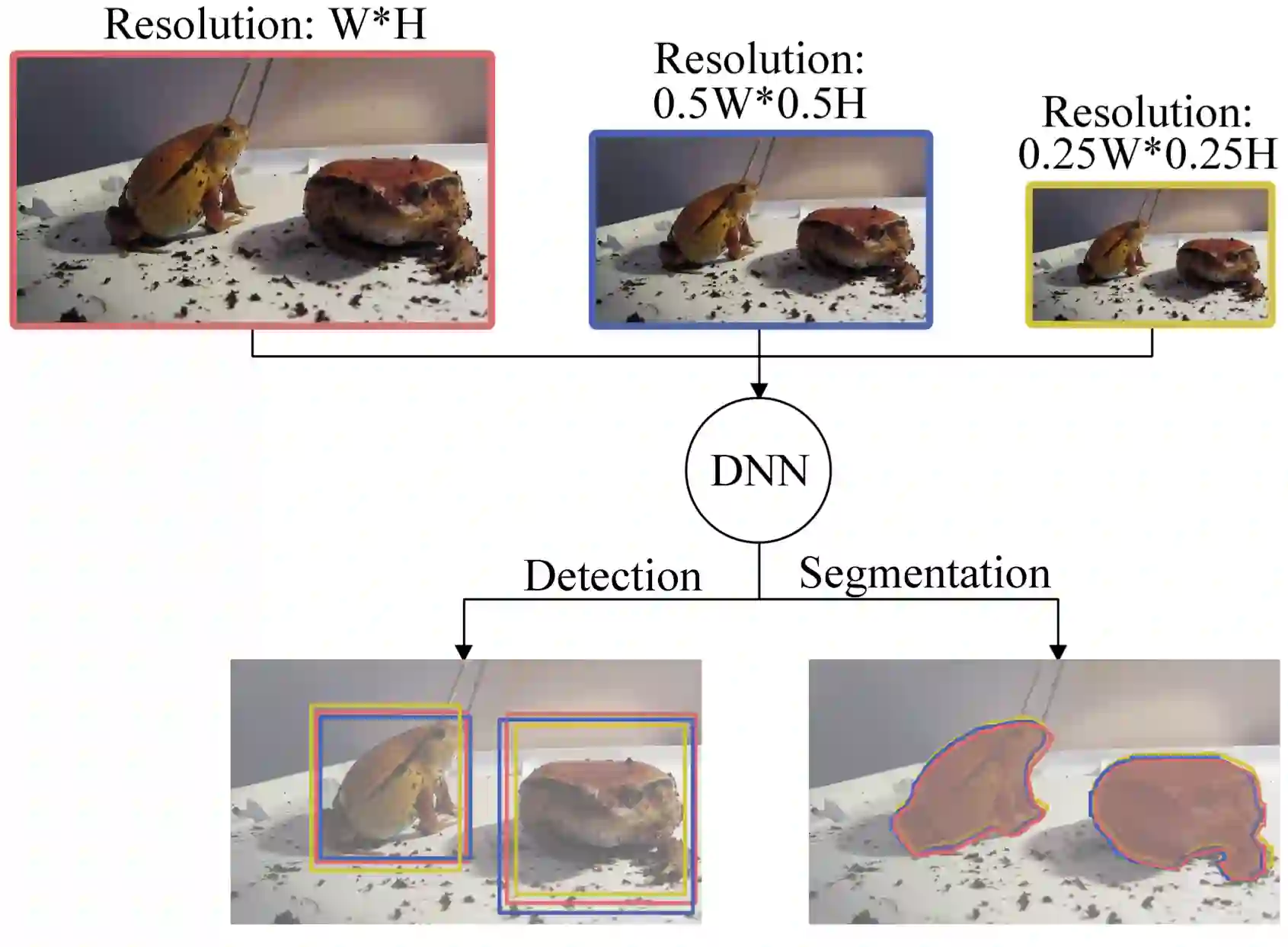
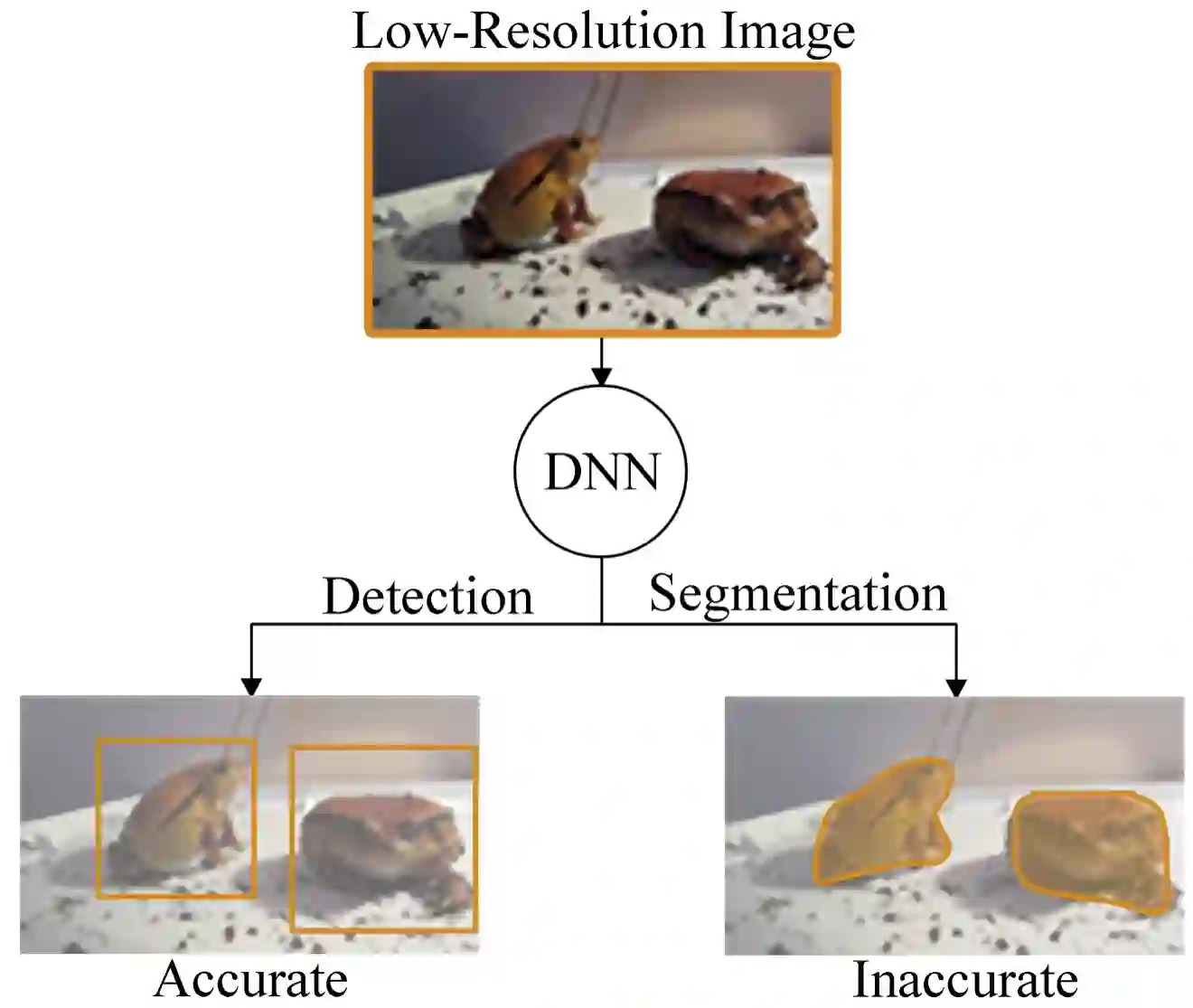
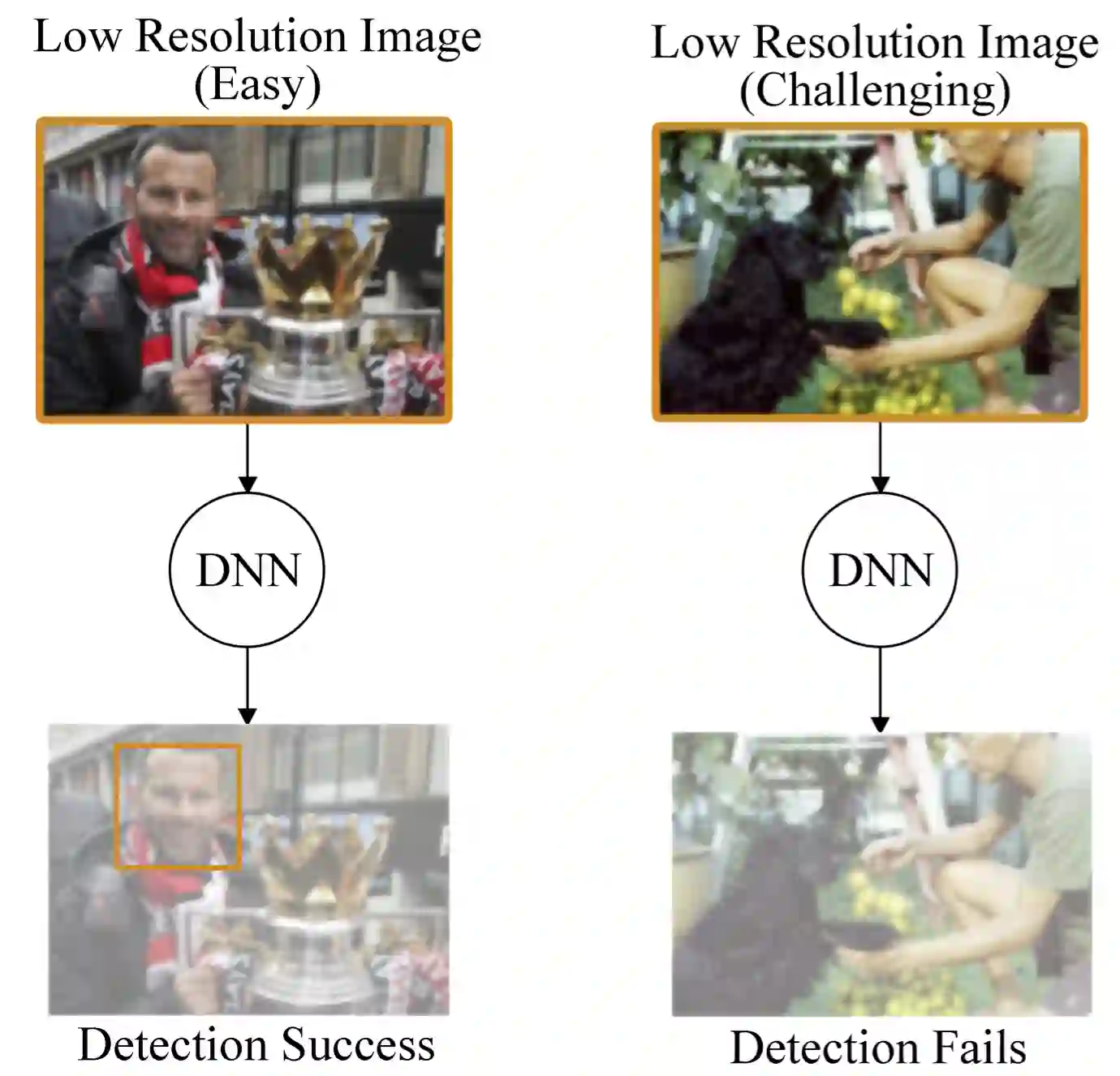
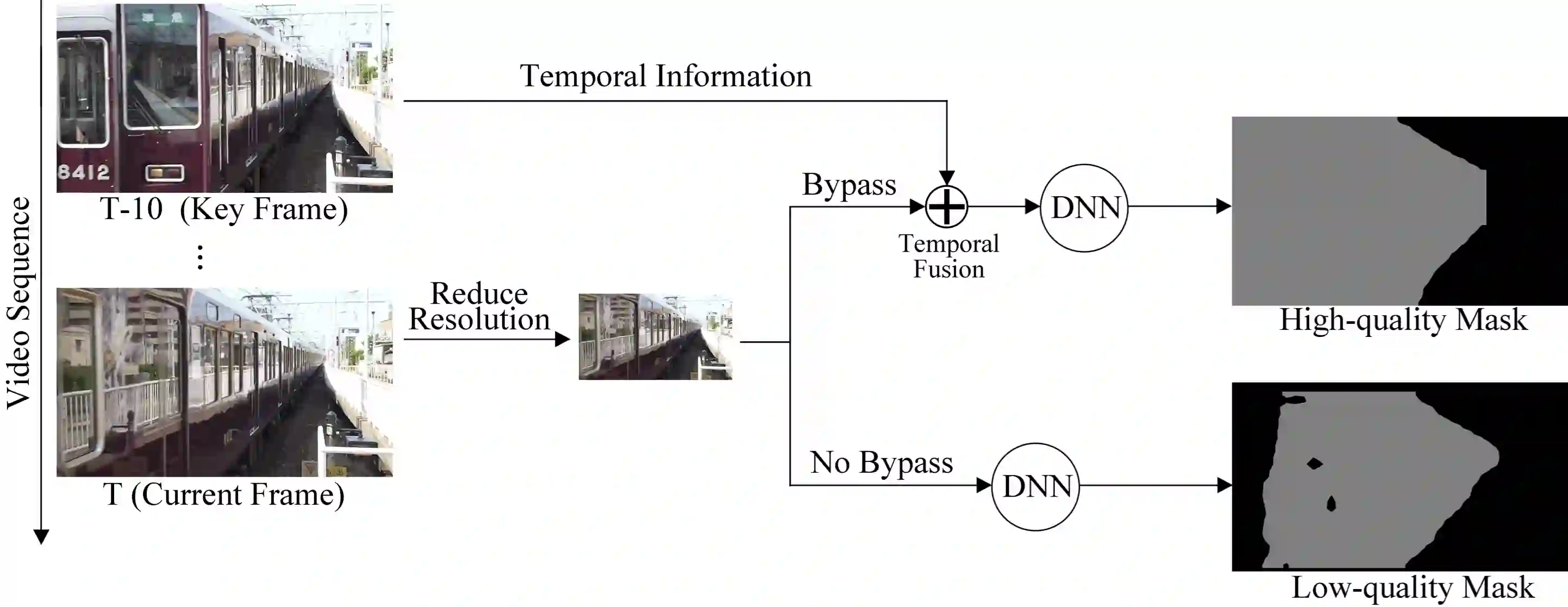
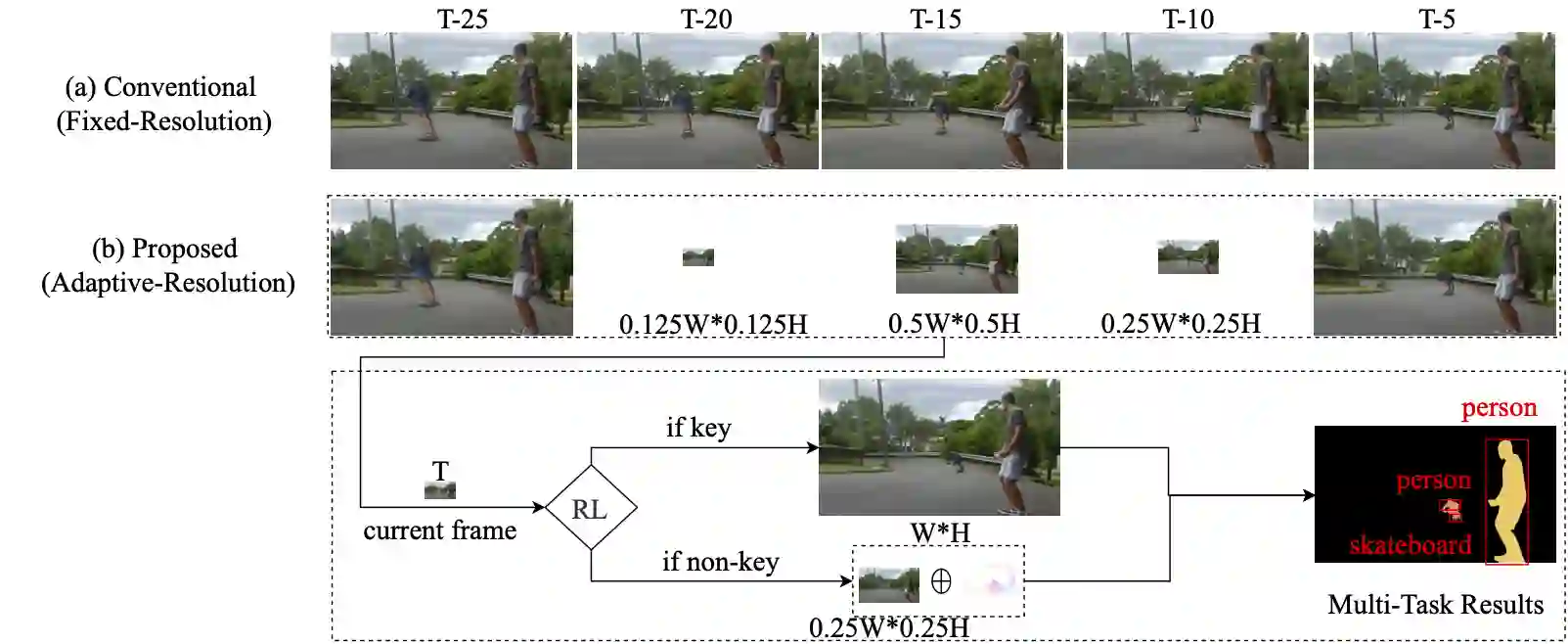
Deep-learning-based video processing has yielded transformative results in recent years. However, the video analytics pipeline is energy-intensive due to high data rates and reliance on complex inference algorithms, which limits its adoption in energy-constrained applications. Motivated by the observation of high and variable spatial redundancy and temporal dynamics in video data streams, we design and evaluate an adaptive-resolution optimization framework to minimize the energy use of multi-task video analytics pipelines. Instead of heuristically tuning the input data resolution of individual tasks, our framework utilizes deep reinforcement learning to dynamically govern the input resolution and computation of the entire video analytics pipeline. By monitoring the impact of varying resolution on the quality of high-dimensional video analytics features, hence the accuracy of video analytics results, the proposed end-to-end optimization framework learns the best non-myopic policy for dynamically controlling the resolution of input video streams to achieve globally optimize energy efficiency. Governed by reinforcement learning, optical flow is incorporated into the framework to minimize unnecessary spatio-temporal redundancy that leads to re-computation, while preserving accuracy. The proposed framework is applied to video instance segmentation which is one of the most challenging machine vision tasks, and the energy consumption efficiency of the proposed framework has significantly surpassed all baseline methods of similar accuracy on the YouTube-VIS dataset.
翻译:然而,视频分析管道由于高数据率和依赖复杂的推算算法,能源密集型,限制了其在能源限制的应用中采用。由于在视频数据流中观测高度和可变的空间冗余和时间动态,我们设计并评价一个适应性分辨率优化框架,以尽量减少多任务视频分析管道的能源使用,从而尽量减少多任务视频分析管道的能源使用。我们的框架不是对单个任务的输入数据解析进行过度调整,而是利用深度强化学习来动态管理投入解析和整个视频分析管道的计算。通过监测不同分辨率对高维视频分析特征质量的影响,从而监测视频分析结果的准确性,我们拟议的端对端优化框架学习如何以动态方式控制对投入视频流的解析以实现全球最佳能效。我们的框架利用了深度强化学习,将光学流纳入框架,以最大限度地减少输入流中的不必要刻度冗余冗余和整个视频分析管道的计算。通过监测不同分辨率对高度视频分析特征质量的影响,从而监测视频分析结果结果的准确性,因此,拟议的端端到端端端优化框架,同时维护了所有拟议机路的准确度框架。