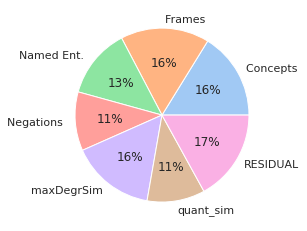
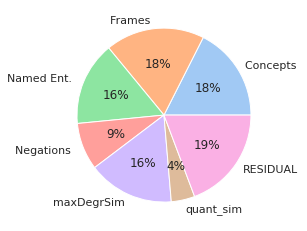
Metrics for graph-based meaning representations (e.g., Abstract Meaning Representation, AMR) can help us uncover key semantic aspects in which two sentences are similar to each other. However, such metrics tend to be slow, rely on parsers, and do not reach state-of-the-art performance when rating sentence similarity. On the other hand, models based on large-pretrained language models, such as S(entence)BERT, show high correlation to human similarity ratings, but lack interpretability. In this paper, we aim at the best of these two worlds, by creating similarity metrics that are highly effective, while also providing an interpretable rationale for their rating. Our approach works in two steps: We first select AMR graph metrics that measure meaning similarity of sentences with respect to key semantic facets, such as, i.a., semantic roles, negation, or quantification. Second, we employ these metrics to induce Semantically Structured Sentence BERT embeddings (S$^3$BERT), which are composed of different meaning aspects captured in different sub-spaces. In our experimental studies, we show that our approach offers a valuable balance between performance and interpretability.
翻译:以图表为基础的含义表示(例如,抽象含义代表、AMR)的计量方法可以帮助我们发现关键语义方面,其中两个句子彼此相似。然而,这类衡量方法往往缓慢,依赖分析者,在评分判决相似时没有达到最先进的性能。另一方面,基于诸如S(entence)BERT等大规模草率语言模型的模型显示与人类相似性评级高度相关,但缺乏可解释性。在本文中,我们的目标是在这两个世界中找到最优的相似性指标,即建立非常有效的相似性指标,同时为其评级提供可解释的理由。我们的方法分为两个步骤:我们首先选择AMR图指标衡量关键语义方面相似性,例如,例如,语义作用,否定,或量化。第二,我们使用这些指标来诱导出具有不同含义、在不同次空间中捕捉到的BEERT嵌入(S=3$BERT),在实验性研究中展示了我们之间具有不同价值平衡性的方法。