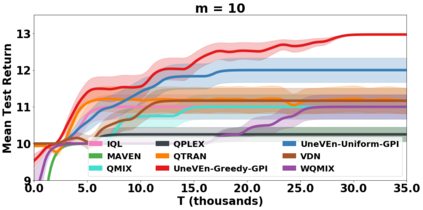
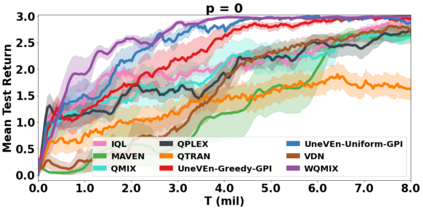
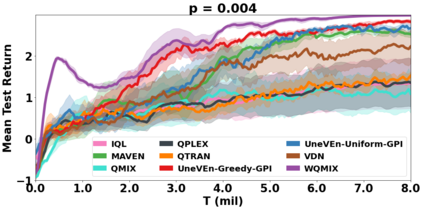
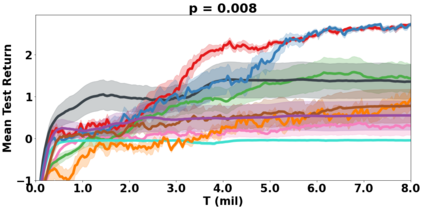
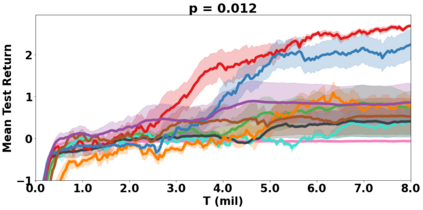
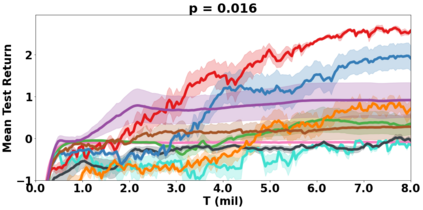
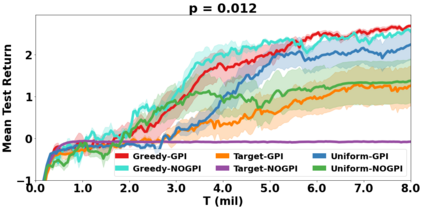
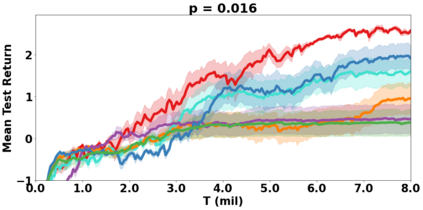
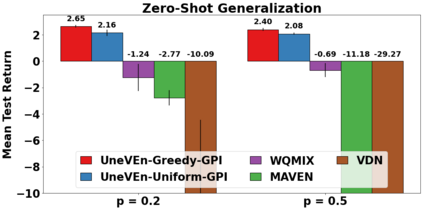
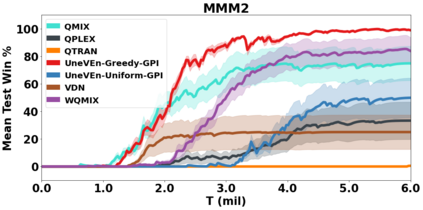
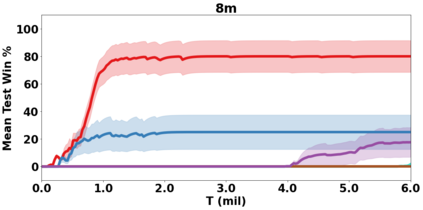
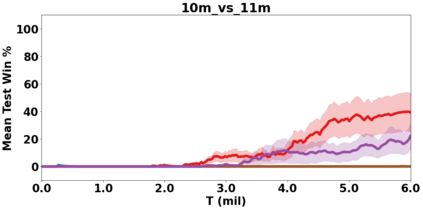
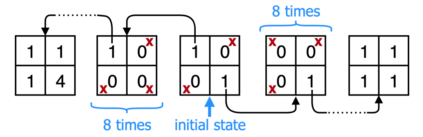
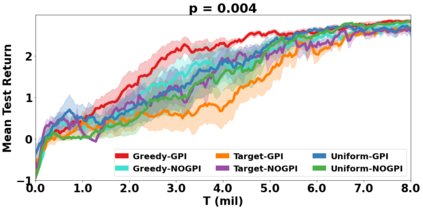
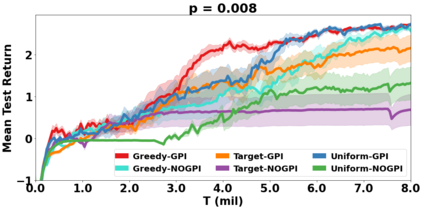
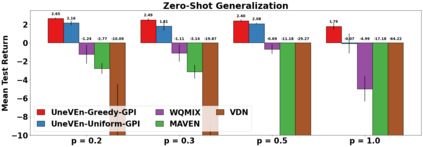
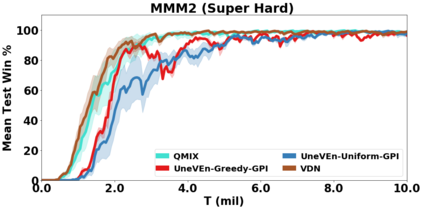
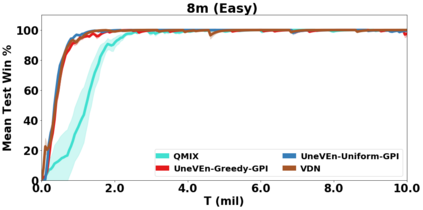
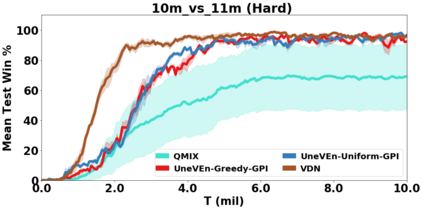
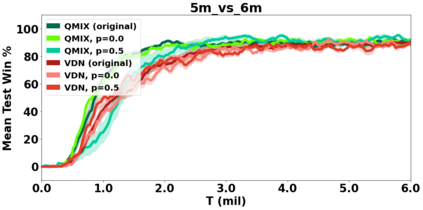
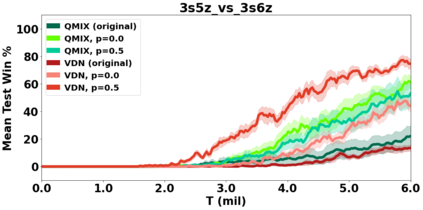
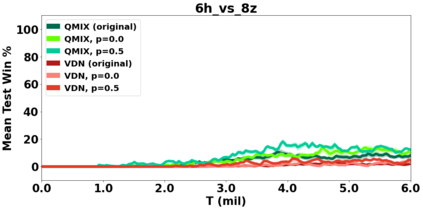
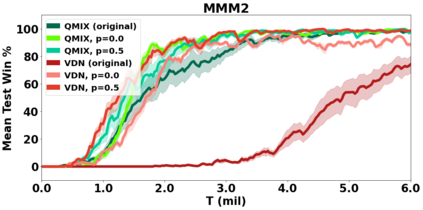
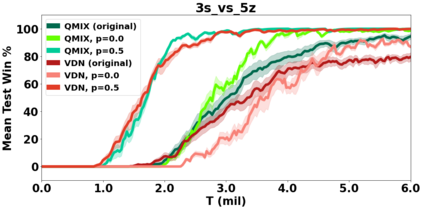
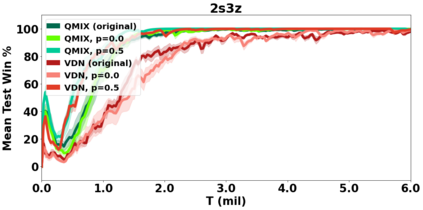
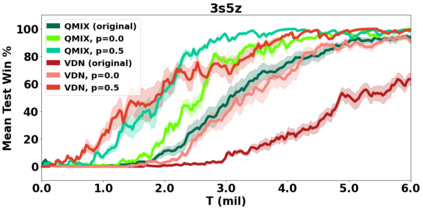
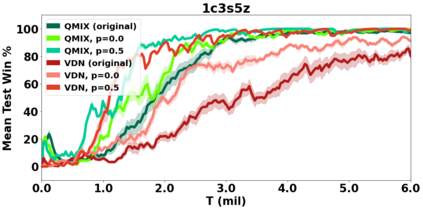
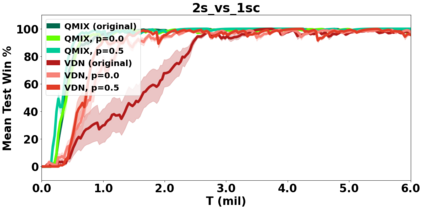
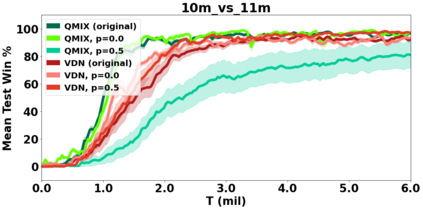
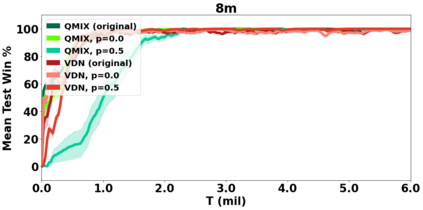
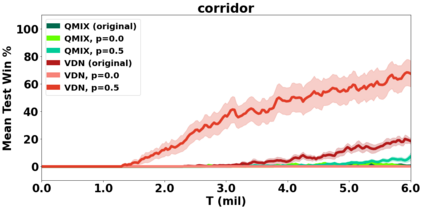
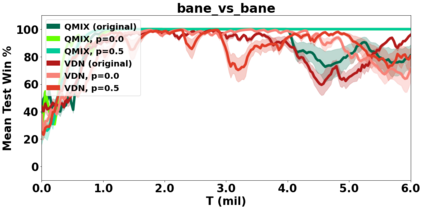
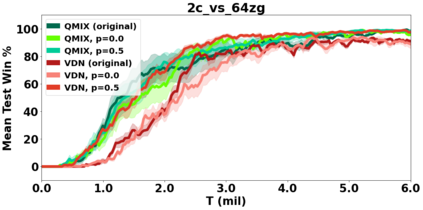
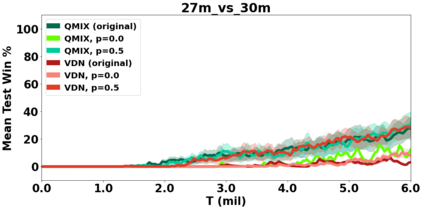
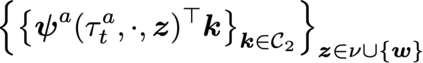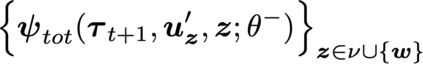VDN and QMIX are two popular value-based algorithms for cooperative MARL that learn a centralized action value function as a monotonic mixing of per-agent utilities. While this enables easy decentralization of the learned policy, the restricted joint action value function can prevent them from solving tasks that require significant coordination between agents at a given timestep. We show that this problem can be overcome by improving the joint exploration of all agents during training. Specifically, we propose a novel MARL approach called Universal Value Exploration (UneVEn) that learns a set of related tasks simultaneously with a linear decomposition of universal successor features. With the policies of already solved related tasks, the joint exploration process of all agents can be improved to help them achieve better coordination. Empirical results on a set of exploration games, challenging cooperative predator-prey tasks requiring significant coordination among agents, and StarCraft II micromanagement benchmarks show that UneVEn can solve tasks where other state-of-the-art MARL methods fail.
翻译:VDN 和 QMIX 是合作MARL的两种流行的基于价值的算法,这些算法学习集中行动价值功能,作为每个代理公用事业的单一组合。这可以方便地将所学政策下放,但有限的联合行动价值功能可以防止他们解决在特定时间步骤上需要代理人之间大量协调的任务。我们表明,可以通过在培训期间改进对所有代理人的共同探索来解决这个问题。具体地说,我们提议一种名为通用价值探索(Uneven)的新型MARL方法,在学习一套相关任务的同时,还学习一套与通用后续特征线性分解相关的任务。随着相关任务已经解决的政策,所有代理人的联合勘探进程可以改进,帮助他们实现更好的协调。一套勘探游戏的经验性结果,挑战需要代理人之间大量协调的合作性掠食者先行任务,StarCraft II微观管理基准显示,UneVen可以解决其他最先进的ML方法失败的任务。