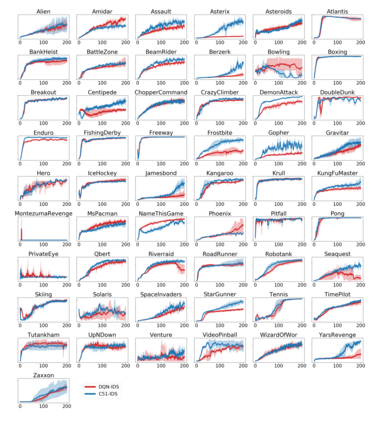
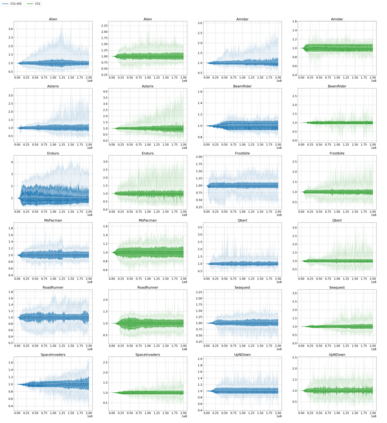
Efficient exploration remains a major challenge for reinforcement learning. One reason is that the variability of the returns often depends on the current state and action, and is therefore heteroscedastic. Classical exploration strategies such as upper confidence bound algorithms and Thompson sampling fail to appropriately account for heteroscedasticity, even in the bandit setting. Motivated by recent findings that address this issue in bandits, we propose to use Information-Directed Sampling (IDS) for exploration in reinforcement learning. As our main contribution, we build on recent advances in distributional reinforcement learning and propose a novel, tractable approximation of IDS for deep Q-learning. The resulting exploration strategy explicitly accounts for both parametric uncertainty and heteroscedastic observation noise. We evaluate our method on Atari games and demonstrate a significant improvement over alternative approaches.
翻译:高效勘探仍然是强化学习的一大挑战。 原因之一是回报的变异性往往取决于当前的状态和行动,因此具有高度失常性。 传统探索策略,如上信任约束算法和汤普森抽样等,即使在土匪的环境下,也无法适当说明异性。 受最近关于土匪问题的调查结果的驱使,我们提议在强化学习中利用信息稀释抽样(IDS)来进行探索。 作为我们的主要贡献,我们在分配强化学习的最新进展的基础上再接再厉,提出了用于深入Q学习的新型、可移植的IDS近似值。由此形成的勘探战略明确说明了参数不确定性和超异性观测噪音。 我们评估了我们关于阿塔里游戏的方法,并展示了相对于替代方法的重大改进。