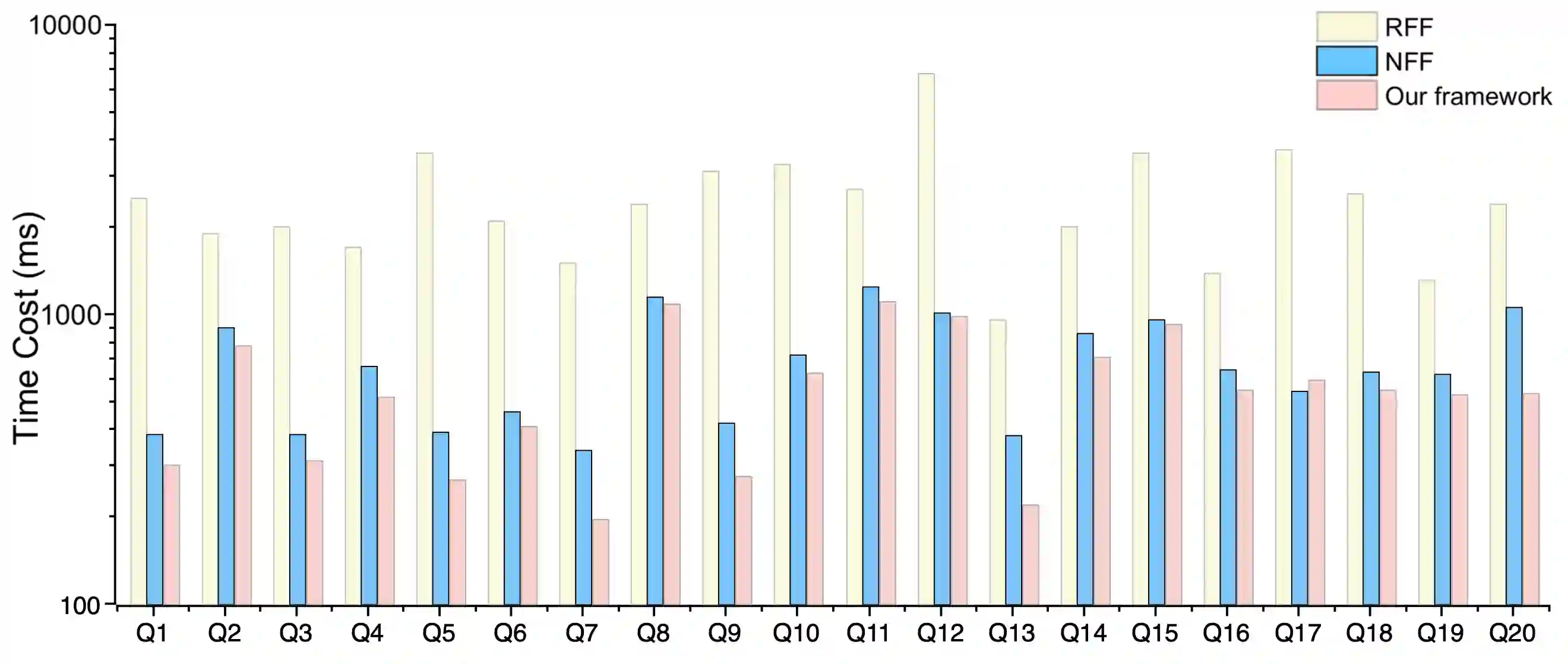
In order to facilitate the accesses of general users to knowledge graphs, an increasing effort is being exerted to construct graph-structured queries of given natural language questions. At the core of the construction is to deduce the structure of the target query and determine the vertices/edges which constitute the query. Existing query construction methods rely on question understanding and conventional graph-based algorithms which lead to inefficient and degraded performances facing complex natural language questions over knowledge graphs with large scales. In this paper, we focus on this problem and propose a novel framework standing on recent knowledge graph embedding techniques. Our framework first encodes the underlying knowledge graph into a low-dimensional embedding space by leveraging generalized local knowledge graphs. Given a natural language question, the learned embedding representations of the knowledge graph are utilized to compute the query structure and assemble vertices/edges into the target query. Extensive experiments were conducted on the benchmark dataset, and the results demonstrate that our framework outperforms state-of-the-art baseline models regarding effectiveness and efficiency.
翻译:为了方便一般用户查阅知识图,正在加紧努力,对特定自然语言问题进行图表结构查询。建设的核心是推断目标查询的结构并确定构成查询的脊椎/边缘。现有的查询构建方法依赖于对问题的了解和传统的图表算法,这些算法导致在大规模知识图上面临复杂的自然语言问题,结果导致低效和退化的性能。在本文件中,我们集中关注这一问题,并提议一个新的框架,以最新的知识图嵌入技术为中心。我们的框架首先通过利用通用的当地知识图将基本知识图编码成一个低维嵌入空间。鉴于一个自然语言问题,知识图的精明嵌入式表示法被用来对查询结构进行编译,并将脊椎/边缘组合到目标查询中。对基准数据集进行了广泛的实验,结果显示,我们的框架在效力和效率方面超过了最新基线模型。