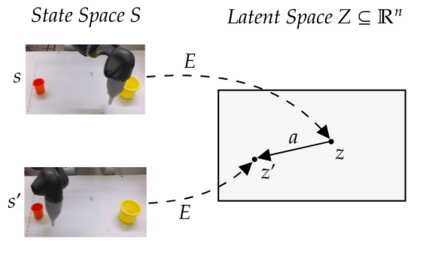
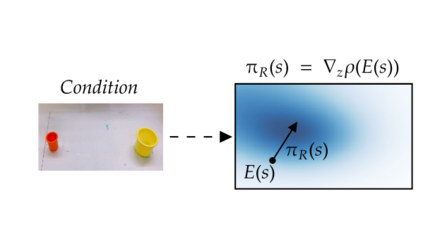
Learning from previously collected datasets of expert data offers the promise of acquiring robotic policies without unsafe and costly online explorations. However, a major challenge is a distributional shift between the states in the training dataset and the ones visited by the learned policy at the test time. While prior works mainly studied the distribution shift caused by the policy during the offline training, the problem of recovering from out-of-distribution states at the deployment time is not very well studied yet. We alleviate the distributional shift at the deployment time by introducing a recovery policy that brings the agent back to the training manifold whenever it steps out of the in-distribution states, e.g., due to an external perturbation. The recovery policy relies on an approximation of the training data density and a learned equivariant mapping that maps visual observations into a latent space in which translations correspond to the robot actions. We demonstrate the effectiveness of the proposed method through several manipulation experiments on a real robotic platform. Our results show that the recovery policy enables the agent to complete tasks while the behavioral cloning alone fails because of the distributional shift problem.
翻译:从以前收集的专家数据集中学习的专家数据有可能在不进行不安全和费用昂贵的在线探索的情况下获得机器人政策。然而,一个重大挑战是各州在培训数据集和测试时学习的政策所访问的州之间的分配变化。虽然以前的工作主要研究了该政策在离线培训期间造成的分配变化,但还没有很好地研究部署时从分配之外的国家中恢复的问题。我们引入了一种回收政策,使代理商在离开分配状态时回到培训的方方面面,例如,由于外部干扰。回收政策依赖于对培训数据密度的近似和将视觉观测映射成与机器人行动相对应的潜在空间的学习的等同绘图。我们通过在真正的机器人平台上进行几次操纵实验来证明拟议方法的有效性。我们的结果显示,回收政策使代理商能够完成任务,而行为克隆仅仅因为分配变化问题而失败。