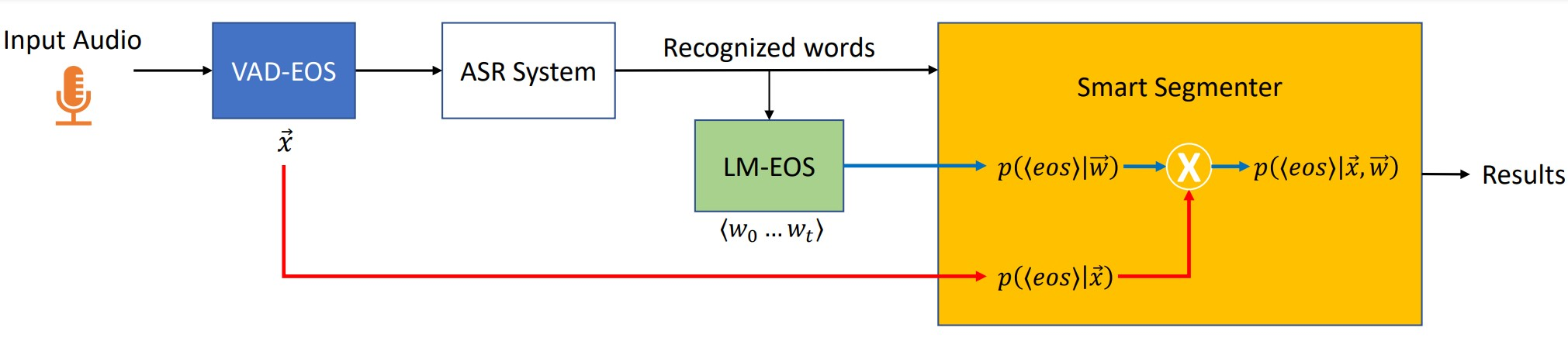
Segmentation for continuous Automatic Speech Recognition (ASR) has traditionally used silence timeouts or voice activity detectors (VADs), which are both limited to acoustic features. This segmentation is often overly aggressive, given that people naturally pause to think as they speak. Consequently, segmentation happens mid-sentence, hindering both punctuation and downstream tasks like machine translation for which high-quality segmentation is critical. Model-based segmentation methods that leverage acoustic features are powerful, but without an understanding of the language itself, these approaches are limited. We present a hybrid approach that leverages both acoustic and language information to improve segmentation. Furthermore, we show that including one word as a look-ahead boosts segmentation quality. On average, our models improve segmentation-F0.5 score by 9.8% over baseline. We show that this approach works for multiple languages. For the downstream task of machine translation, it improves the translation BLEU score by an average of 1.05 points.
翻译:连续自动语音识别(ASR)通常使用静音超时或语音活动探测器(VADs),它们都局限于音频功能。这种分解往往过于激进,因为人们自然会暂停思考,因此分解发生中点,阻碍标点和下游工作,如高质量分解至关重要的机器翻译。借助声频特征的模型分解方法是强大的,但不了解语言本身,这些方法是有限的。我们呈现一种混合方法,利用声频和语言信息来改进分解。此外,我们显示包括一个单词作为外头助推法质量。平均而言,我们的模型将分解-F0.5比基线提高9.8%。我们显示,这一方法适用于多种语言。对于下游机器翻译来说,它提高了BLEU的分数,平均为1.05分。