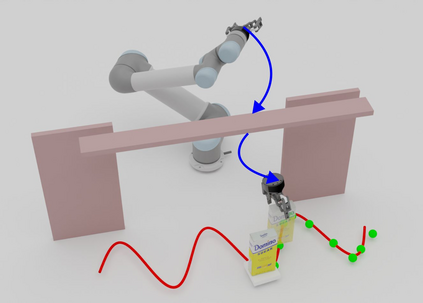
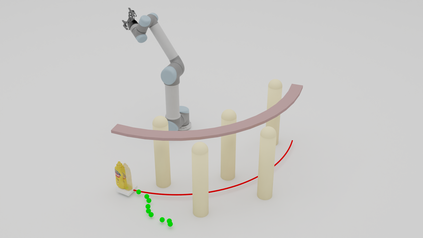
Grasping moving objects is a challenging task that combines multiple submodules such as object pose predictor, arm motion planner, etc. Each submodule operates under its own set of meta-parameters. For example, how far the pose predictor should look into the future (i.e., look-ahead time) and the maximum amount of time the motion planner can spend planning a motion (i.e., time budget). Many previous works assign fixed values to these parameters either heuristically or through grid search; however, at different moments within a single episode of dynamic grasping, the optimal values should vary depending on the current scene. In this work, we learn a meta-controller through reinforcement learning to control the look-ahead time and time budget dynamically. Our extensive experiments show that the meta-controller improves the grasping success rate (up to 12% in the most cluttered environment) and reduces grasping time, compared to the strongest baseline. Our meta-controller learns to reason about the reachable workspace and maintain the predicted pose within the reachable region. In addition, it assigns a small but sufficient time budget for the motion planner. Our method can handle different target objects, trajectories, and obstacles. Despite being trained only with 3-6 randomly generated cuboidal obstacles, our meta-controller generalizes well to 7-9 obstacles and more realistic out-of-domain household setups with unseen obstacle shapes. Video is available at https://youtu.be/CwHq77wFQqI.
翻译:切换移动对象是一项具有挑战性的任务,它结合了多个子模块,例如物体的预测器、手臂运动规划仪等。每个子模块在其自身的一组元参数下运行。例如,组合预测器对未来应看多远(即,观光前时间)和运动规划员可以规划运动(即,时间预算)的最大时间。许多先前的作品都为这些参数指定固定值,要么是超速的,要么是通过网格搜索;然而,在动态捕捉的某一时刻的不同时刻,最佳值应该根据当前场景而变化。在这项工作中,我们通过强化学习学习来控制视觉前的时间和时间预算来学习一个元控制器。我们广泛的实验显示,组合控制器可以提高掌握运动成功率(在最拥挤的环境中高达12%),并比最强的基线减少掌握时间。我们的元控制器元控制器了解可到达的工作空间的原因,并维持在可到达的区域内的预测面容。此外,我们通过强化的强化的系统障碍来学习一个元控制器控制器 。此外,我们所训练的常规的日历中,它会设置一个微但足够多的时间方法。