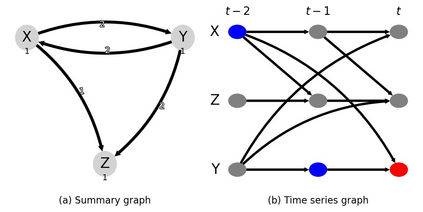
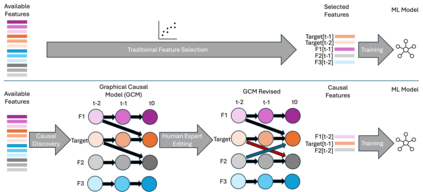
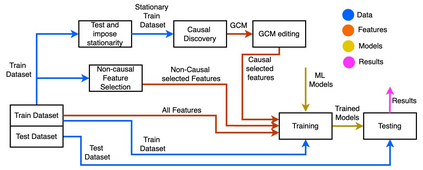
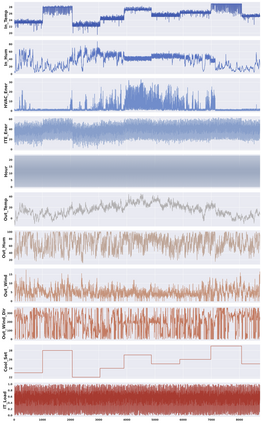
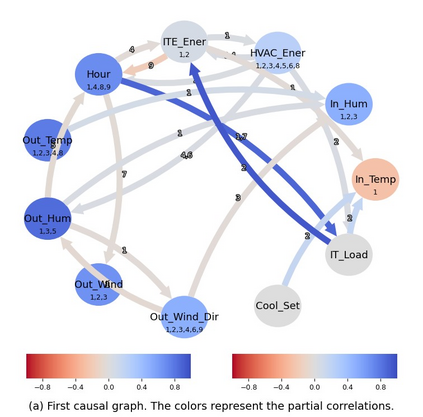
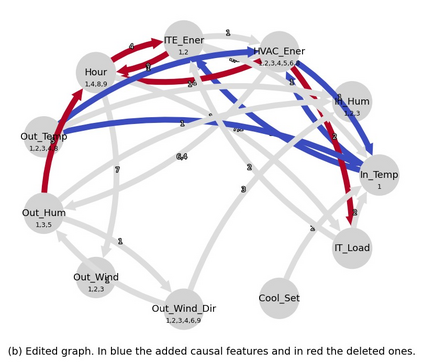
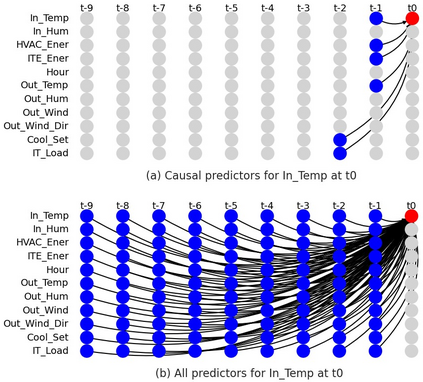
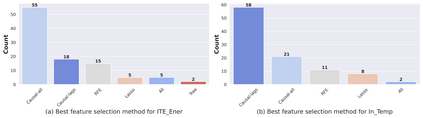
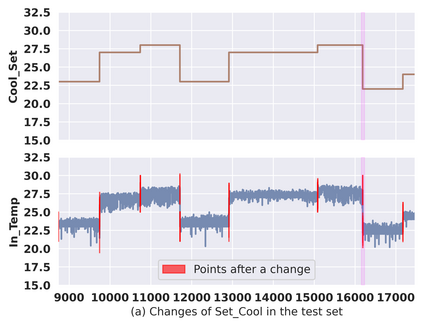
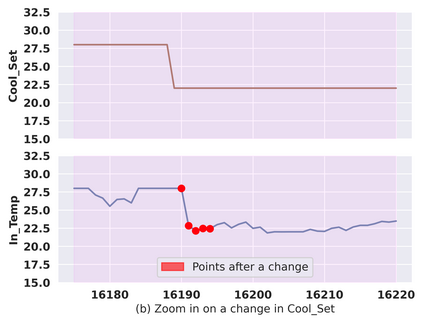
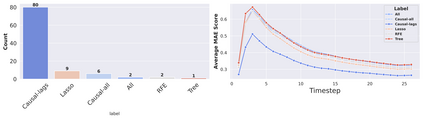
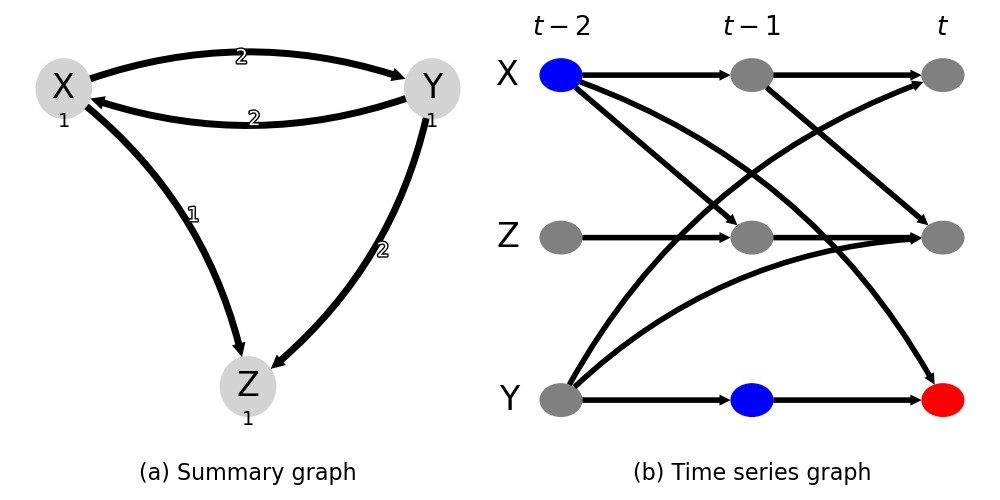
Classical machine learning techniques often struggle with overfitting and unreliable predictions when exposed to novel conditions. Introducing causality into the modelling process offers a promising way to mitigate these challenges by enhancing interpretability and predictive reliability. However, constructing an initial causal graph manually using domain knowledge is a time-consuming, particularly in complex time series with numerous variables. To address this, causal discovery algorithms can provide a preliminary causal structure that domain experts can refine. This study investigates causal feature selection with domain knowledge using a data centre system as an example. We use simulated time-series data to compare different causal feature selection with traditional machine-learning feature selection methods. Our results show that predictions based on causal features are more robust and interpretable compared to those derived from traditional methods. These findings underscore the potential of combining causal discovery algorithms with human expertise to improve machine learning applications.
翻译:暂无翻译