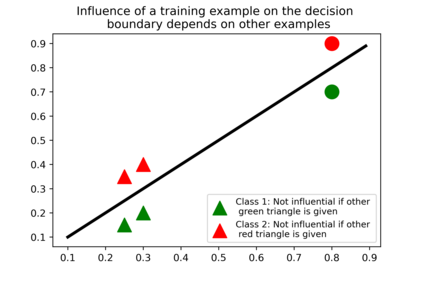
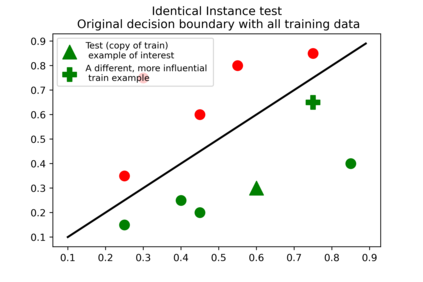
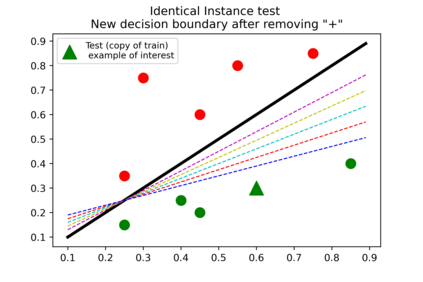
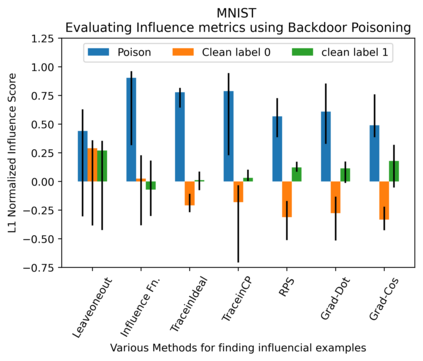
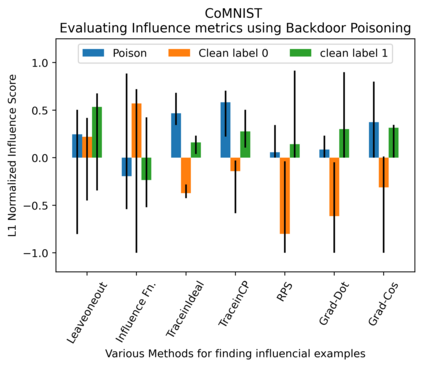
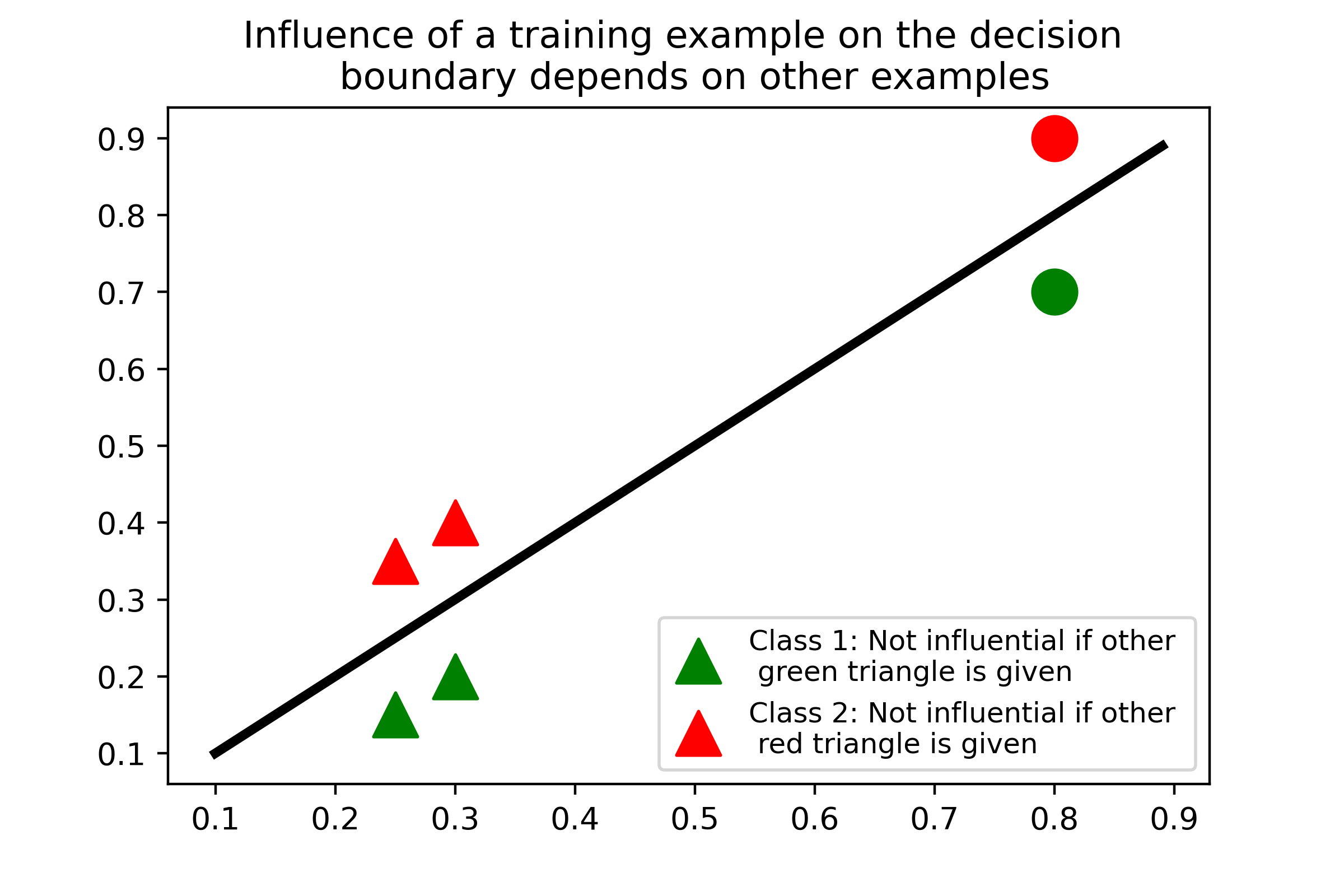
Several instance-based explainability methods for finding influential training examples for test-time decisions have been proposed recently, including Influence Functions, TraceIn, Representer Point Selection, Grad-Dot, and Grad-Cos. Typically these methods are evaluated using LOO influence (Cook's distance) as a gold standard, or using various heuristics. In this paper, we show that all of the above methods are unstable, i.e., extremely sensitive to initialization, ordering of the training data, and batch size. We suggest that this is a natural consequence of how in the literature, the influence of examples is assumed to be independent of model state and other examples -- and argue it is not. We show that LOO influence and heuristics are, as a result, poor metrics to measure the quality of instance-based explanations, and instead propose to evaluate such explanations by their ability to detect poisoning attacks. Further, we provide a simple, yet effective baseline to improve all of the above methods and show how it leads to very significant improvements on downstream tasks.
翻译:最近提出了若干基于实例的解释方法,用于为测试时的决定寻找有影响力的培训实例,包括影响函数、TraceIn、代表点选择、Grad-Dot和Grad-Cos。 通常,这些方法是使用LOO影响(Cook的距离)作为金本位标准,或使用各种牛皮法来评估的。在本文件中,我们表明所有上述方法都是不稳定的,即对初始化极为敏感,对培训数据排序和批量大小。我们提出,这是文献如何假定例子的影响独立于模型状态和其他例子的自然结果,我们争辩说,事实并非如此。我们表明,LOO影响和超自然学作为衡量实例解释质量的尺度因此很差,我们提议用其检测中毒袭击的能力来评价这种解释。此外,我们提供了一个简单而有效的基线来改进所有上述方法,并表明它如何导致下游任务的重大改进。