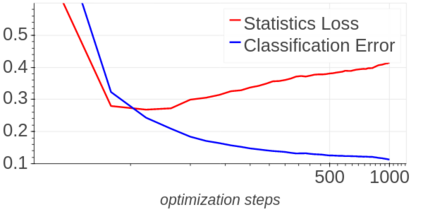
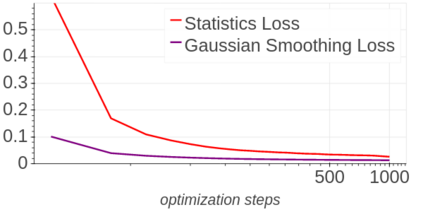
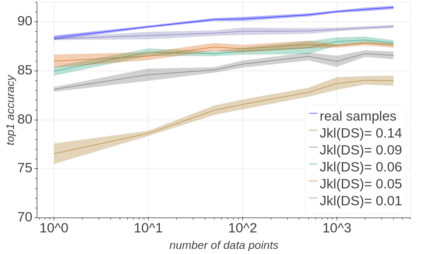
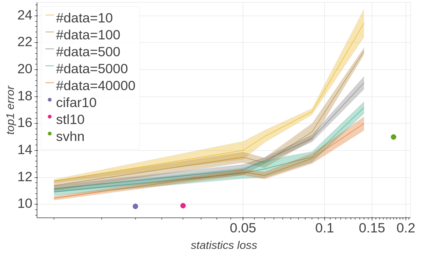
Background: Recently, an extensive amount of research has been focused on compressing and accelerating Deep Neural Networks (DNNs). So far, high compression rate algorithms required the entire training dataset, or its subset, for fine-tuning and low precision calibration process. However, this requirement is unacceptable when sensitive data is involved as in medical and biometric use-cases. Contributions: We present three methods for generating synthetic samples from trained models. Then, we demonstrate how these samples can be used to fine-tune or to calibrate quantized models with negligible accuracy degradation compared to the original training set --- without using any real data in the process. Furthermore, we suggest that our best performing method, leveraging intrinsic batch normalization layers' statistics of a trained model, can be used to evaluate data similarity. Our approach opens a path towards genuine data-free model compression, alleviating the need for training data during deployment.
翻译:背景:最近,大量研究侧重于压缩和加速深神经网络(DNNs),迄今为止,高压缩率算法要求整个培训数据集或其子集进行微调和低精确校准过程,然而,当敏感数据如医学和生物鉴别使用案例涉及敏感数据时,这一要求是不可接受的。 贡献:我们提出了从经过训练的模型中生成合成样品的三种方法。然后,我们展示了这些样本如何用于微调或校准与最初的成套培训相比精确度可忽略不计的模型 -- -- 而不使用任何实际数据。此外,我们建议,我们采用最佳的操作方法,利用经过训练的模型固有的分批正常化层统计数据,来评估数据相似性。我们的方法开辟了一条通往真正无数据模型压缩的道路,从而减轻了部署期间对培训数据的需求。