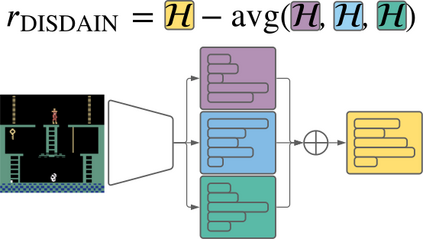
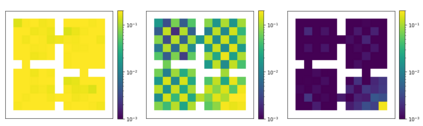
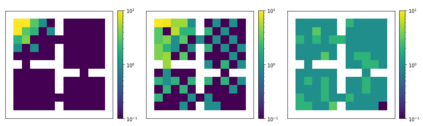
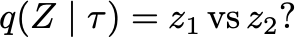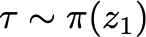Unsupervised skill learning objectives (Gregor et al., 2016, Eysenbach et al., 2018) allow agents to learn rich repertoires of behavior in the absence of extrinsic rewards. They work by simultaneously training a policy to produce distinguishable latent-conditioned trajectories, and a discriminator to evaluate distinguishability by trying to infer latents from trajectories. The hope is for the agent to explore and master the environment by encouraging each skill (latent) to reliably reach different states. However, an inherent exploration problem lingers: when a novel state is actually encountered, the discriminator will necessarily not have seen enough training data to produce accurate and confident skill classifications, leading to low intrinsic reward for the agent and effective penalization of the sort of exploration needed to actually maximize the objective. To combat this inherent pessimism towards exploration, we derive an information gain auxiliary objective that involves training an ensemble of discriminators and rewarding the policy for their disagreement. Our objective directly estimates the epistemic uncertainty that comes from the discriminator not having seen enough training examples, thus providing an intrinsic reward more tailored to the true objective compared to pseudocount-based methods (Burda et al., 2019). We call this exploration bonus discriminator disagreement intrinsic reward, or DISDAIN. We demonstrate empirically that DISDAIN improves skill learning both in a tabular grid world (Four Rooms) and the 57 games of the Atari Suite (from pixels). Thus, we encourage researchers to treat pessimism with DISDAIN.
翻译:不受监督的技能学习目标( Gregor et al., 2016年, Eysenbach et al., 2018年) 使代理商能够在没有外部奖励的情况下学习丰富的行为经验。 他们同时培训一项政策,以产生可辨别的潜在条件轨迹, 并且通过试图从轨迹中推断出潜影来评估可辨别性。 代理商的希望是通过鼓励每一种技能( 老手)可靠地到达不同的州来探索和掌握环境。 然而,一个固有的探索问题依然存在: 当一个新兴国家实际遇到时, 歧视者一定不会看到足够的培训数据来产生准确和自信的技能分类, 从而导致对代理商的内在奖赏较低, 并有效惩罚为实际最大化目标所需的勘探类型。 为了消除这种内在的悲观主义, 我们从一个信息增益的辅助目标, 包括训练一个歧视者团, 并奖励他们的政策。 我们的目标直接估计了来自歧视者没有看到足够的培训榜样的教益, 也不一定看到足够的D 的教益 。 因此, 我们用一个内在的教益性地奖赏性原则 。