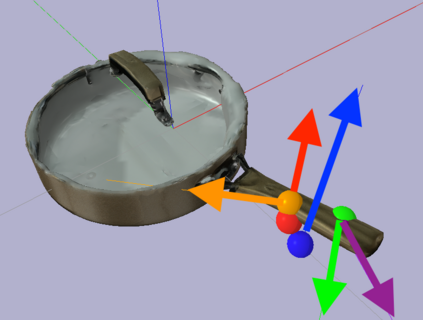
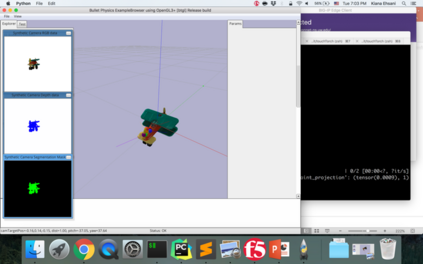
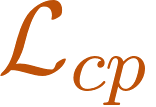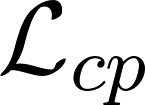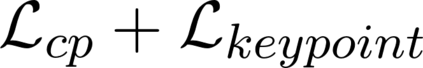When we humans look at a video of human-object interaction, we can not only infer what is happening but we can even extract actionable information and imitate those interactions. On the other hand, current recognition or geometric approaches lack the physicality of action representation. In this paper, we take a step towards a more physical understanding of actions. We address the problem of inferring contact points and the physical forces from videos of humans interacting with objects. One of the main challenges in tackling this problem is obtaining ground-truth labels for forces. We sidestep this problem by instead using a physics simulator for supervision. Specifically, we use a simulator to predict effects and enforce that estimated forces must lead to the same effect as depicted in the video. Our quantitative and qualitative results show that (a) we can predict meaningful forces from videos whose effects lead to accurate imitation of the motions observed, (b) by jointly optimizing for contact point and force prediction, we can improve the performance on both tasks in comparison to independent training, and (c) we can learn a representation from this model that generalizes to novel objects using few shot examples.
翻译:当我们人类看人类与物体相互作用的视频时,我们不仅可以推断正在发生的事情,而且我们甚至可以提取可操作的信息并模仿这些互动。另一方面,目前的认识或几何方法缺乏行动代表的物理性。在本文中,我们朝着更实际地理解行动的方向迈出了一步。我们处理从人类与物体相互作用的视频中推断接触点和物理力量的问题。解决这一问题的主要挑战之一是获得力量的地面真相标签。我们绕过这个问题,而是使用物理模拟器进行监督。具体地说,我们使用模拟器来预测效果,并强制执行估计力量必须产生与视频中描述的相同的效果。我们的定量和定性结果显示:(a) 我们可以预测通过视频产生的有意义的力量,其影响导致准确模仿所观察到的动作;(b) 通过联合优化接触点和武力预测,我们可以在与独立培训相比,改进这两项任务的业绩。以及(c) 我们可以从这个模型中学习一种代表,即利用少量的镜头来概括到新的物体。