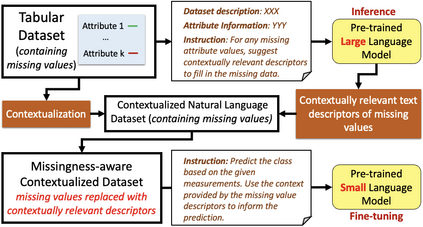
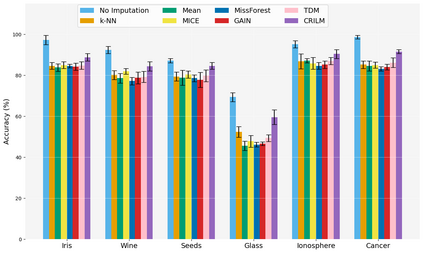
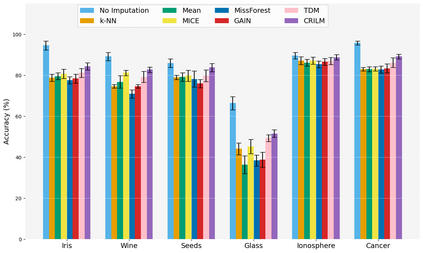
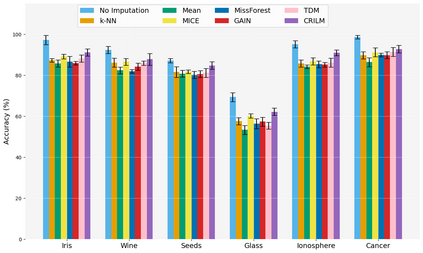
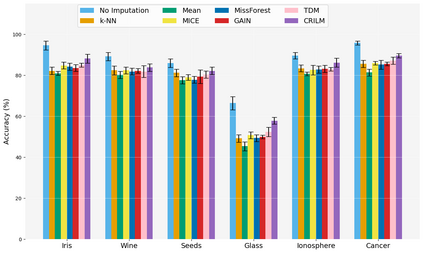
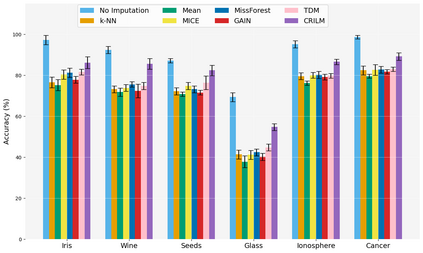
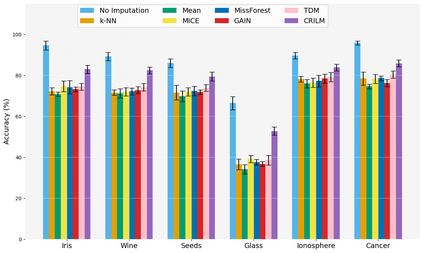
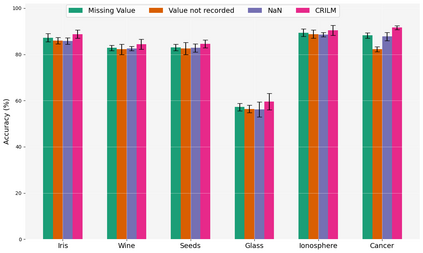
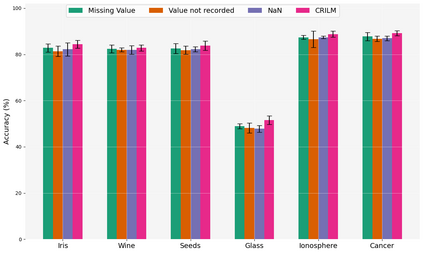
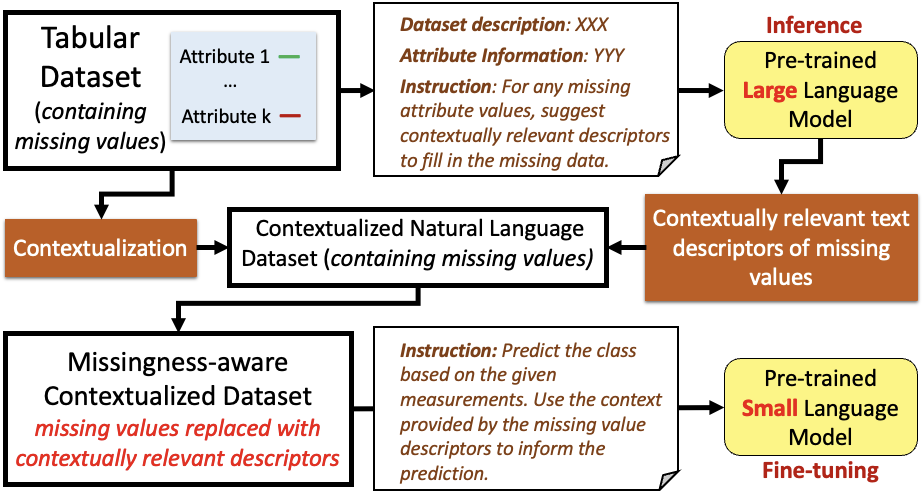
This paper presents a novel approach named \textbf{C}ontextually \textbf{R}elevant \textbf{I}mputation leveraging pre-trained \textbf{L}anguage \textbf{M}odels (\textbf{CRILM}) for handling missing data in tabular datasets. Instead of relying on traditional numerical estimations, CRILM uses pre-trained language models (LMs) to create contextually relevant descriptors for missing values. This method aligns datasets with LMs' strengths, allowing large LMs to generate these descriptors and small LMs to be fine-tuned on the enriched datasets for enhanced downstream task performance. Our evaluations demonstrate CRILM's superior performance and robustness across MCAR, MAR, and challenging MNAR scenarios, with up to a 10\% improvement over the best-performing baselines. By mitigating biases, particularly in MNAR settings, CRILM improves downstream task performance and offers a cost-effective solution for resource-constrained environments.
翻译:暂无翻译