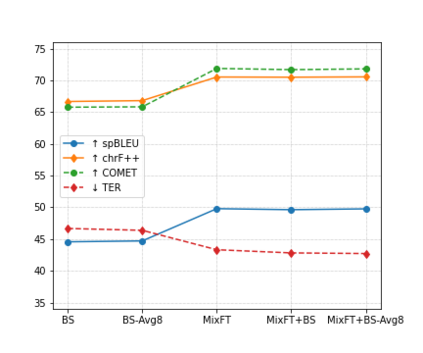
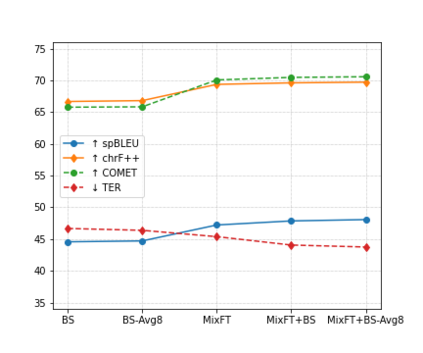
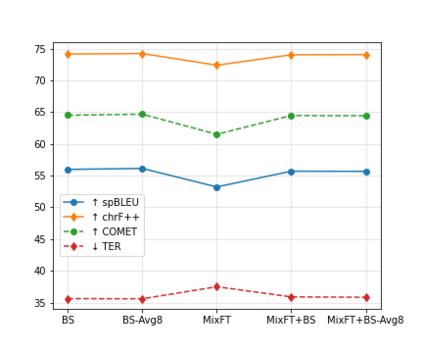
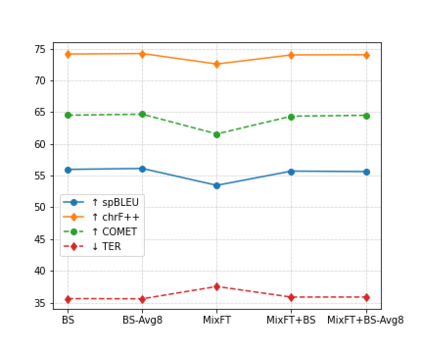
Preservation of domain knowledge from the source to target is crucial in any translation workflow. It is common in the translation industry to receive highly specialized projects, where there is hardly any parallel in-domain data. In such scenarios where there is insufficient in-domain data to fine-tune Machine Translation (MT) models, producing translations that are consistent with the relevant context is challenging. In this work, we propose a novel approach to domain adaptation leveraging state-of-the-art pretrained language models (LMs) for domain-specific data augmentation for MT, simulating the domain characteristics of either (a) a small bilingual dataset, or (b) the monolingual source text to be translated. Combining this idea with back-translation, we can generate huge amounts of synthetic bilingual in-domain data for both use cases. For our investigation, we use the state-of-the-art Transformer architecture. We employ mixed fine-tuning to train models that significantly improve translation of in-domain texts. More specifically, in both scenarios, our proposed methods achieve improvements of approximately 5-6 BLEU and 2-3 BLEU, respectively, on the Arabic-to-English and English-to-Arabic language pairs. Furthermore, the outcome of human evaluation corroborates the automatic evaluation results.
翻译:在任何翻译工作流程中,从源源到目标的域知识保护至关重要。翻译行业通常都会接受高度专业化的项目,因为那里几乎没有平行的内地数据。在这种情况下,如果没有足够的内部数据来微调机器翻译模型(MT)模型,则产生符合相关背景的翻译是具有挑战性的。在这项工作中,我们提出一种新的办法,利用最新的、最先进的、经过预先培训的语言模型(LMS)进行适应,为MT提供具体领域的数据增强,模拟(a) 一个小型的双语数据集或(b) 需要翻译的单语文文本的域特性。在这种想法与回译相结合的情况下,我们可以产生大量合成的双语内部数据,供两个案件使用。我们的调查使用最新版的变换器结构。我们采用混合的微调方法,以培训大大改进内部文本翻译的模型。更具体地说,在两种情况下,我们提出的方法都分别改进了(a) 5-6 BLEU 和 2-3 BLEU,分别改进了阿拉伯-英语和英语的自动结果。