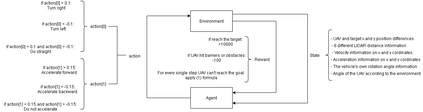
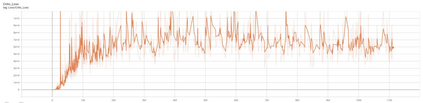
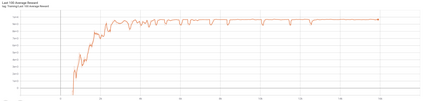
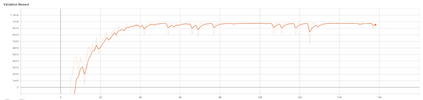
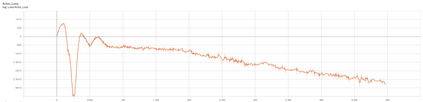
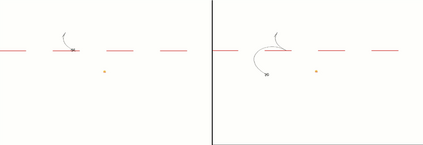
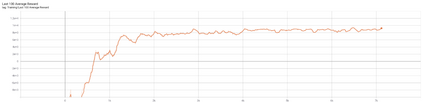
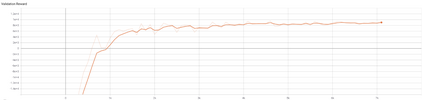
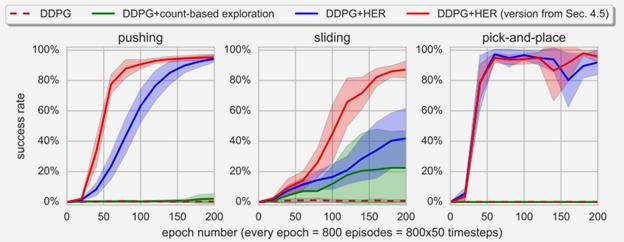
The advent of artificial intelligence technology paved the way of many researches to be made within air combat sector. Academicians and many other researchers did a research on a prominent research direction called autonomous maneuver decision of UAV. Elaborative researches produced some outcomes, but decisions that include Reinforcement Learning(RL) came out to be more efficient. There have been many researches and experiments done to make an agent reach its target in an optimal way, most prominent are Genetic Algorithm(GA) , A star, RRT and other various optimization techniques have been used. But Reinforcement Learning is the well known one for its success. In DARPHA Alpha Dogfight Trials, reinforcement learning prevailed against a real veteran F16 human pilot who was trained by Boeing. This successor model was developed by Heron Systems. After this accomplishment, reinforcement learning bring tremendous attention on itself. In this research we aimed our UAV which has a dubin vehicle dynamic property to move to the target in two dimensional space in an optimal path using Twin Delayed Deep Deterministic Policy Gradients (TD3) and used in experience replay Hindsight Experience Replay(HER).We did tests on two different environments and used simulations.
翻译:人工智能技术的出现为在空中作战部门进行许多研究铺平了道路。 学者和许多其他研究人员对一个称为UAV自主操作决定的突出研究方向进行了研究。 精细研究产生了一些结果,但包括加强学习(RL)在内的决定更有效率。 已经进行了许多研究和实验,使一个代理以最佳方式达到目标,最突出的是遗传Algorithm(GA)、一颗恒星、RRT和其他各种优化技术。 但强化学习是其成功之处,但众所周知的是它的成功。 在DARPHA Apha Dogfight 实验中, 强化学习优于一个真正的老战士F16人类实验,该实验由Boeing培训。这一后继模型由Heron Systems开发。完成后,强化学习本身引起极大关注。 在这项研究中,我们针对我们的UAVAV, 它拥有一个杜宾飞行器动态属性,可以在两个空间向目标移动,一个最佳路径是使用双延缓深振动政策分级(TD3),并用于两次模拟环境。