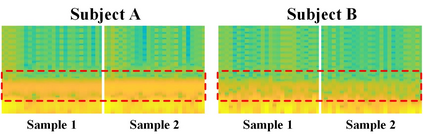
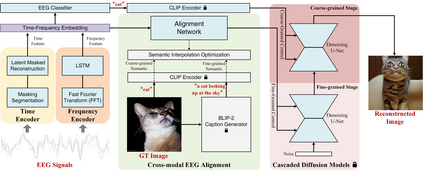
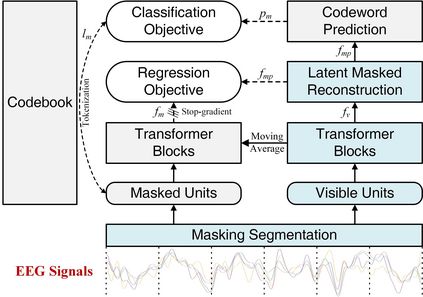
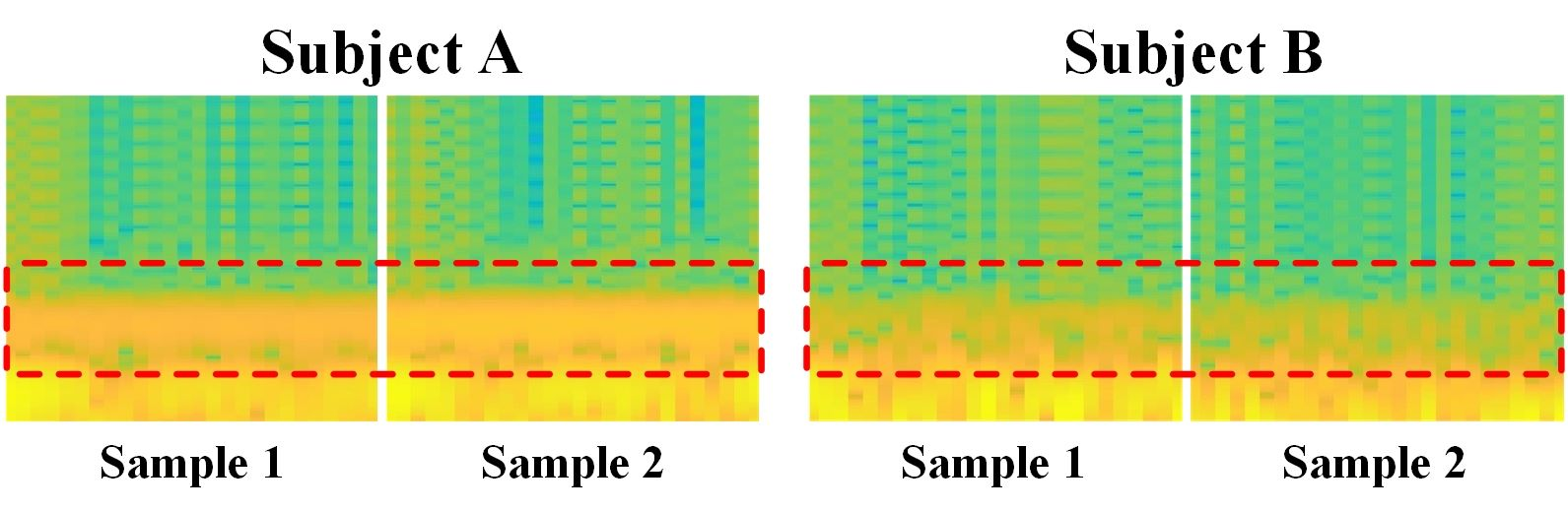
Analyzing and reconstructing visual stimuli from brain signals effectively advances understanding of the human visual system. However, the EEG signals are complex and contain a amount of noise. This leads to substantial limitations in existing works of visual stimuli reconstruction from EEG, such as difficulties in aligning EEG embeddings with the fine-grained semantic information and a heavy reliance on additional large self-collected dataset for training. To address these challenges, we propose a novel approach called BrainVis. Firstly, we divide the EEG signals into various units and apply a self-supervised approach on them to obtain EEG time-domain features, in an attempt to ease the training difficulty. Additionally, we also propose to utilize the frequency-domain features to enhance the EEG representations. Then, we simultaneously align EEG time-frequency embeddings with the interpolation of the coarse and fine-grained semantics in the CLIP space, to highlight the primary visual components and reduce the cross-modal alignment difficulty. Finally, we adopt the cascaded diffusion models to reconstruct images. Our proposed BrainVis outperforms state of the arts in both semantic fidelity reconstruction and generation quality. Notably, we reduce the training data scale to 10% of the previous work.
翻译:暂无翻译