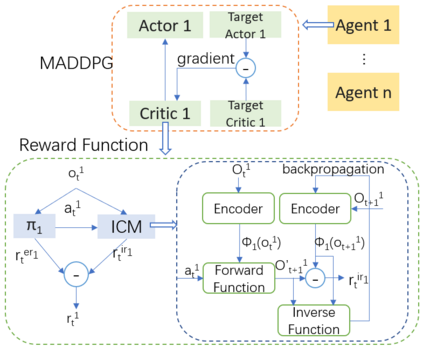
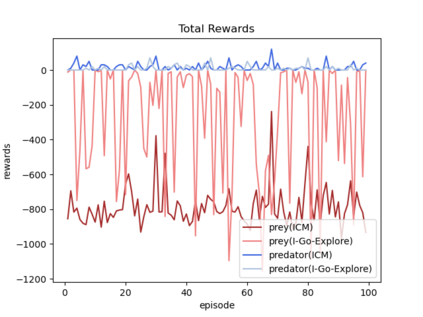
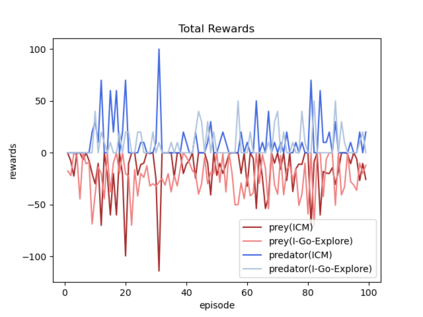
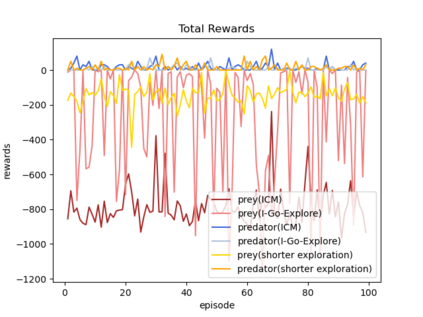
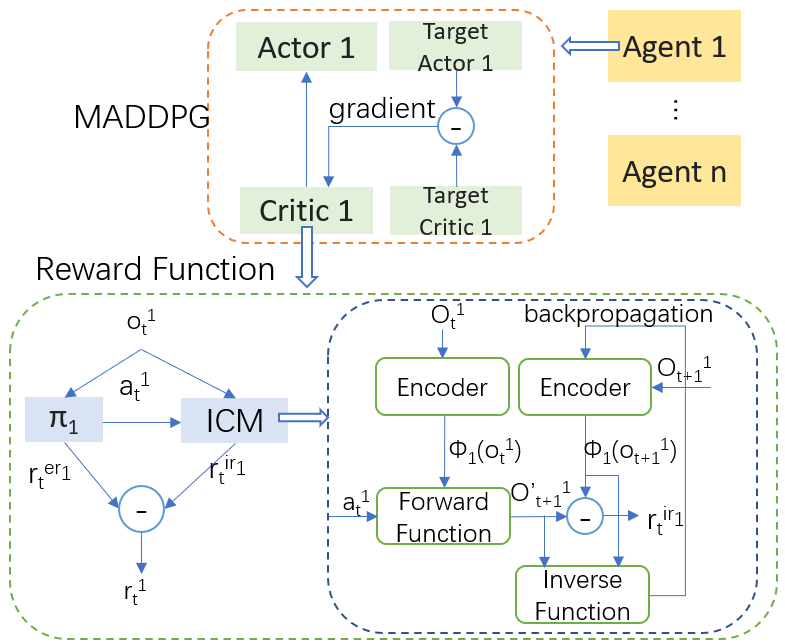
Sparsity of rewards while applying a deep reinforcement learning method negatively affects its sample-efficiency. A viable solution to deal with the sparsity of rewards is to learn via intrinsic motivation which advocates for adding an intrinsic reward to the reward function to encourage the agent to explore the environment and expand the sample space. Though intrinsic motivation methods are widely used to improve data-efficient learning in the reinforcement learning model, they also suffer from the so-called detachment problem. In this article, we discuss the limitations of intrinsic curiosity module in sparse-reward multi-agent reinforcement learning and propose a method called I-Go-Explore that combines the intrinsic curiosity module with the Go-Explore framework to alleviate the detachment problem.
翻译:在采用深层强化学习方法的同时,奖励的公平性会对其抽样效率产生不利影响。处理奖励的宽度的可行解决办法是通过内在动机学习,这种内在动机倡导在奖励功能中增加内在奖励以鼓励代理人探索环境和扩大抽样空间。虽然在强化学习模式中广泛采用内在动机方法来改进数据效率学习,但也有所谓的隔离问题。在本条中,我们讨论了微薄回报多试剂强化学习中内在好奇单元的局限性,并提出一种称为I-Go-Explore的方法,将内在好奇单元与Go-Explore框架结合起来,以缓解隔离问题。