【论文推荐】最新六篇强化学习相关论文—Sublinear、机器阅读理解、加速强化学习、对抗性奖励学习、人机交互
【导读】专知内容组整理了最近六篇强化学习(Reinforcement Learning)相关文章,为大家进行介绍,欢迎查看!
1. Multiagent Soft Q-Learning
作者:Ermo Wei,Drew Wicke,David Freelan,Sean Luke
机构:George Mason University
摘要:Policy gradient methods are often applied to reinforcement learning in continuous multiagent games. These methods perform local search in the joint-action space, and as we show, they are susceptable to a game-theoretic pathology known as relative overgeneralization. To resolve this issue, we propose Multiagent Soft Q-learning, which can be seen as the analogue of applying Q-learning to continuous controls. We compare our method to MADDPG, a state-of-the-art approach, and show that our method achieves better coordination in multiagent cooperative tasks, converging to better local optima in the joint action space.
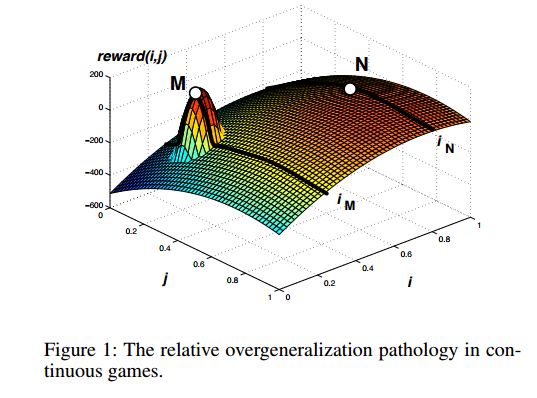
期刊:arXiv, 2018年4月26日
网址:
http://www.zhuanzhi.ai/document/8f0ac64488ab8fa83554b4da6cc2f69d
2. Variance Reduction Methods for Sublinear Reinforcement Learning(Sublinear强化学习的方差缩减方法)
作者:Sham Kakade,Mengdi Wang,Lin F. Yang
机构:Princeton University,University of Washington
摘要:This work considers the problem of provably optimal reinforcement learning for episodic finite horizon MDPs, i.e. how an agent learns to maximize his/her long term reward in an uncertain environment. The main contribution is in providing a novel algorithm --- Variance-reduced Upper Confidence Q-learning (vUCQ) --- which enjoys a regret bound of $\widetilde{O}(\sqrt{HSAT} + H^5SA)$, where the $T$ is the number of time steps the agent acts in the MDP, $S$ is the number of states, $A$ is the number of actions, and $H$ is the (episodic) horizon time. This is the first regret bound that is both sub-linear in the model size and asymptotically optimal. The algorithm is sub-linear in that the time to achieve $\epsilon$-average regret for any constant $\epsilon$ is $O(SA)$, which is a number of samples that is far less than that required to learn any non-trivial estimate of the transition model (the transition model is specified by $O(S^2A)$ parameters). The importance of sub-linear algorithms is largely the motivation for algorithms such as $Q$-learning and other "model free" approaches. vUCQ algorithm also enjoys minimax optimal regret in the long run, matching the $\Omega(\sqrt{HSAT})$ lower bound. Variance-reduced Upper Confidence Q-learning (vUCQ) is a successive refinement method in which the algorithm reduces the variance in $Q$-value estimates and couples this estimation scheme with an upper confidence based algorithm. Technically, the coupling of both of these techniques is what leads to the algorithm enjoying both the sub-linear regret property and the asymptotically optimal regret.

期刊:arXiv, 2018年4月26日
网址:
http://www.zhuanzhi.ai/document/298d70f33245af2313394e0f6de96a73
3. Reinforced Mnemonic Reader for Machine Reading Comprehension(基于强化记忆的机器阅读理解)
作者:Minghao Hu,Yuxing Peng,Zhen Huang,Xipeng Qiu,Furu Wei,Ming Zhou
机构:Fudan University,National University of Defense Technology
摘要:In this paper, we introduce the Reinforced Mnemonic Reader for machine reading comprehension tasks, which enhances previous attentive readers in two aspects. First, a reattention mechanism is proposed to refine current attentions by directly accessing to past attentions that are temporally memorized in a multi-round alignment architecture, so as to avoid the problems of attention redundancy and attention deficiency. Second, a new optimization approach, called dynamic-critical reinforcement learning, is introduced to extend the standard supervised method. It always encourages to predict a more acceptable answer so as to address the convergence suppression problem occurred in traditional reinforcement learning algorithms. Extensive experiments on the Stanford Question Answering Dataset (SQuAD) show that our model achieves state-of-the-art results. Meanwhile, our model outperforms previous systems by over 6% in terms of both Exact Match and F1 metrics on two adversarial SQuAD datasets.
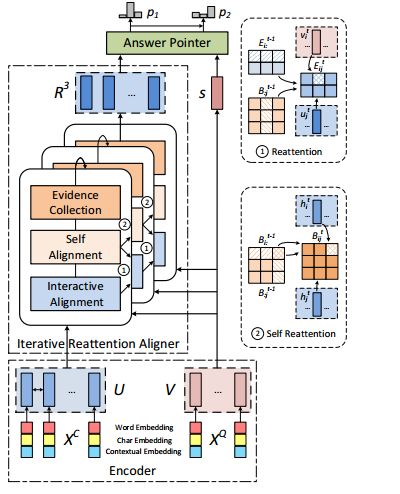
期刊:arXiv, 2018年4月25日
网址:
http://www.zhuanzhi.ai/document/37c93c1bdb68c3559d4f5f1740093d7d
4. Accelerated Reinforcement Learning(加速强化学习)
作者:K. Lakshmanan
摘要:Policy gradient methods are widely used in reinforcement learning algorithms to search for better policies in the parameterized policy space. They do gradient search in the policy space and are known to converge very slowly. Nesterov developed an accelerated gradient search algorithm for convex optimization problems. This has been recently extended for non-convex and also stochastic optimization. We use Nesterov's acceleration for policy gradient search in the well-known actor-critic algorithm and show the convergence using ODE method. We tested this algorithm on a scheduling problem. Here an incoming job is scheduled into one of the four queues based on the queue lengths. We see from experimental results that algorithm using Nesterov's acceleration has significantly better performance compared to algorithm which do not use acceleration. To the best of our knowledge this is the first time Nesterov's acceleration has been used with actor-critic algorithm.
期刊:arXiv, 2018年4月25日
网址:
http://www.zhuanzhi.ai/document/23e73fe759219ab8d58317acce28dc5f
5. No Metrics Are Perfect: Adversarial Reward Learning for Visual Storytelling(没有一个标准是完美的:对视觉叙事的对抗性奖励学习)
作者:Xin Wang,Wenhu Chen,Yuan-Fang Wang,William Yang Wang
机构:University of California
摘要:Though impressive results have been achieved in visual captioning, the task of generating abstract stories from photo streams is still a little-tapped problem. Different from captions, stories have more expressive language styles and contain many imaginary concepts that do not appear in the images. Thus it poses challenges to behavioral cloning algorithms. Furthermore, due to the limitations of automatic metrics on evaluating story quality, reinforcement learning methods with hand-crafted rewards also face difficulties in gaining an overall performance boost. Therefore, we propose an Adversarial REward Learning (AREL) framework to learn an implicit reward function from human demonstrations, and then optimize policy search with the learned reward function. Though automatic evaluation indicates slight performance boost over state-of-the-art (SOTA) methods in cloning expert behaviors, human evaluation shows that our approach achieves significant improvement in generating more human-like stories than SOTA systems.
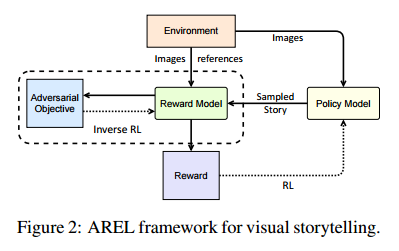
期刊:arXiv, 2018年4月25日
网址:
http://www.zhuanzhi.ai/document/5dc12a9a8438755a167e2aa4a12f3fff
6. Neural Network Based Reinforcement Learning for Audio-Visual Gaze Control in Human-Robot Interaction(用基于神经网络的强化学习做人机交互中的视听注视控制)
作者:Stéphane Lathuilière,Benoit Massé,Pablo Mesejo,Radu Horaud
摘要:This paper introduces a novel neural network-based reinforcement learning approach for robot gaze control. Our approach enables a robot to learn and to adapt its gaze control strategy for human-robot interaction neither with the use of external sensors nor with human supervision. The robot learns to focus its attention onto groups of people from its own audio-visual experiences, independently of the number of people, of their positions and of their physical appearances. In particular, we use a recurrent neural network architecture in combination with Q-learning to find an optimal action-selection policy; we pre-train the network using a simulated environment that mimics realistic scenarios that involve speaking/silent participants, thus avoiding the need of tedious sessions of a robot interacting with people. Our experimental evaluation suggests that the proposed method is robust against parameter estimation, i.e. the parameter values yielded by the method do not have a decisive impact on the performance. The best results are obtained when both audio and visual information is jointly used. Experiments with the Nao robot indicate that our framework is a step forward towards the autonomous learning of socially acceptable gaze behavior.
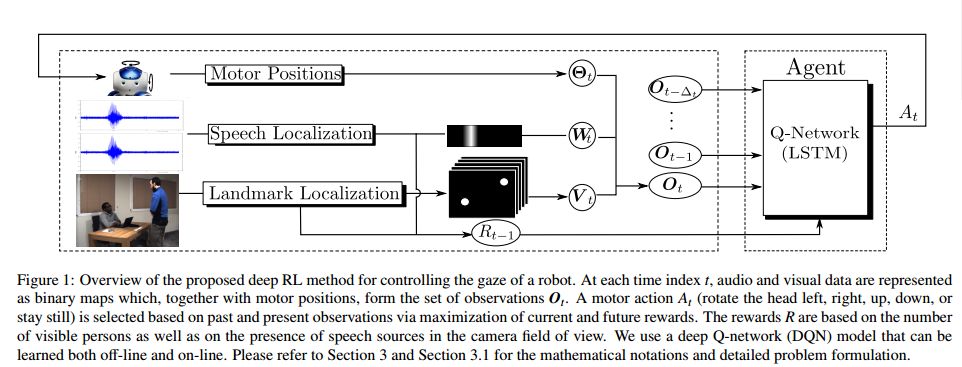
期刊:arXiv, 2018年4月23日
网址:
http://www.zhuanzhi.ai/document/1a62223dcd16d5d4af934daaba9c11b6
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知



