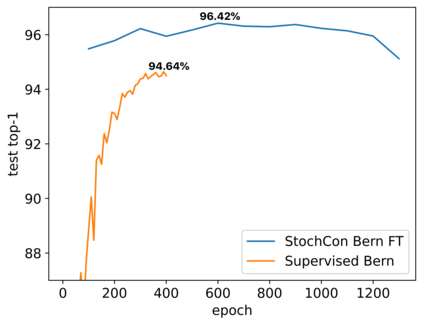
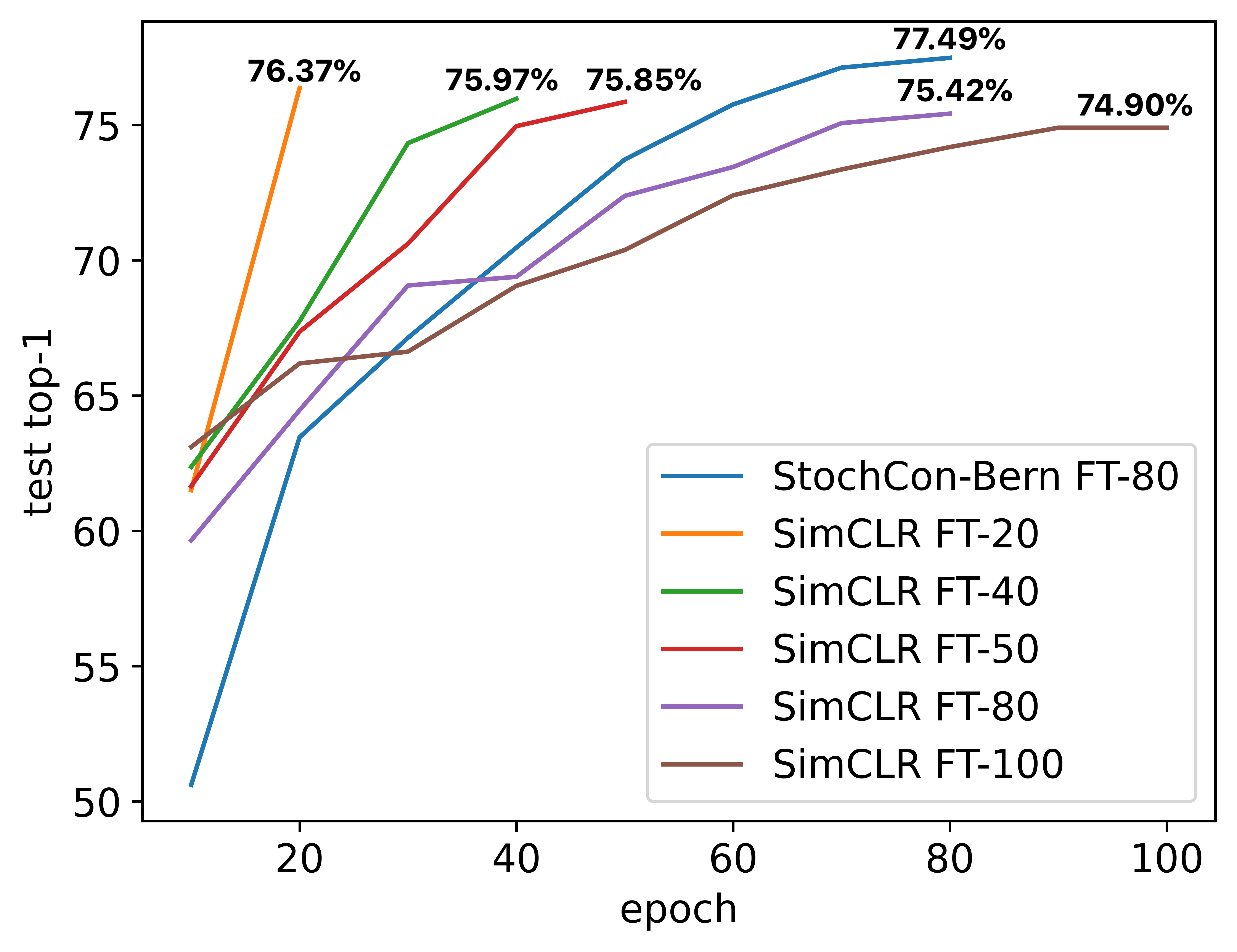
While state-of-the-art contrastive Self-Supervised Learning (SSL) models produce results competitive with their supervised counterparts, they lack the ability to infer latent variables. In contrast, prescribed latent variable (LV) models enable attributing uncertainty, inducing task specific compression, and in general allow for more interpretable representations. In this work, we introduce LV approximations to large scale contrastive SSL models. We demonstrate that this addition improves downstream performance (resulting in 96.42% and 77.49% test top-1 fine-tuned performance on CIFAR10 and ImageNet respectively with a ResNet50) as well as producing highly compressed representations (588x reduction) that are useful for interpretability, classification and regression downstream tasks.
翻译:虽然最先进的对比式自我监督学习(SSL)模式与受监督的同行产生竞争结果,但它们缺乏预测潜在变数的能力,相反,规定的潜在变数(LV)模式可以归结不确定性,诱发特定任务压缩,并一般允许更多的可解释的表述。在这项工作中,我们引入了大规模反差式的SSL模型的LV近似值。我们证明,这一添加提高了下游性能(分别导致96.42%和77.49%测试CIFAR10和图像网上一级1级的微调性能,以及ResNet50, 并产生了对可解释性、分类和回归下游任务有用的高度压缩的表(588x递减)。