深度互学习-Deep Mutual Learning:三人行必有我师
编者按:更高性能的深度神经网络往往伴随着愈加庞大的参数量,而大量的计算需求使其难以部署在移动端。为此,精巧的网络结构设计(如MobileNet、ShuffleNet)、模型压缩策略(剪枝、二值化等)及其他优化方法应运而生。
Hinton等人在2015年提出的模型蒸馏算法,利用预训练好的大网络当作教师来向小网络传递知识,从而提高小网络性能。而模型蒸馏算法需要有提前预训练好的大网络,且仅可对小网络进行单向的知识传递。古人云“三人行必有我师焉”,本文作者提出了一种“深度互学习Deep Mutual Learning”策略,使得小网络之间能够互相学习共同进步。
1.研究动机
近几年来,深度神经网络在计算机视觉、语音识别、语言翻译等领域中取得了令人瞩目的成果,为了完成更加复杂的信息处理任务,网络在设计上不断增加深度或宽度,使得模型参数量越来越大,如经典的VGG、Inception、ResNet系列网络。尽管更深或更宽的神经网络取得了更好的性能,大量计算需求使得它们难以部署在资源条件有限的环境中,如手机、平板、车载等移动端应用。这促使研究者们采用各种各样的方法去探索更高效的模型,如更精巧的网络结构设计MobileNet和ShuffleNet,还有网络压缩、剪枝、二值化,以及比较有趣的模型蒸馏等。
模型蒸馏算法由Hinton等人在2015年提出,利用一个预训练好的大网络当作教师来提供小网络额外的知识即平滑后的概率估计,实验表明小网络通过模仿大网络估计的类别概率,优化过程变得更容易,且表现出与大网络相近甚至更好的性能。然而模型蒸馏算法需要有提前预训练好的大网络,且大网络在学习过程中保持固定,仅对小网络进行单向的知识传递,难以从小网络的学习状态中得到反馈信息来对训练过程进行优化调整。
我们尝试探索一种能够学习到更强大小网络的训练机制—深度互学习,即采用多个网络同时进行训练,每个网络在训练过程中不仅接受来自真值标记的监督,还参考同伴网络的学习经验来进一步提升泛化能力。在整个过程中,两个网络之间不断分享学习经验,实现互相学习共同进步。
2.算法描述
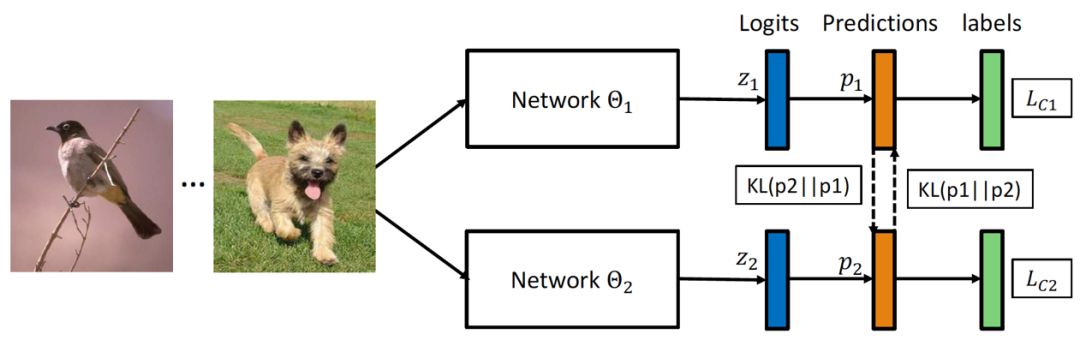
图1 深度互学习算法框架
具体来说,每个网络在学习过程中有两个损失函数,一个是传统的监督损失函数,采用交叉熵损失来度量网络预测的目标类别与真实标签之间的差异,另一个是网络间的交互损失函数,采用KL散度来度量两个网络预测概率分布之间的差异。公式表示为
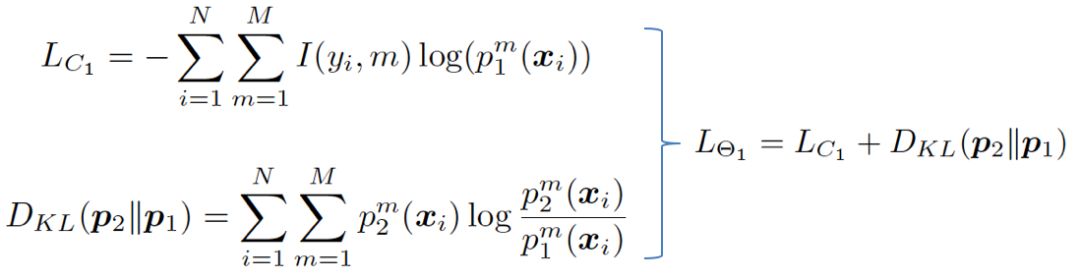
采用这两种损失函数,不仅可以使得网络学习到如何区分不同的类别,还能够使其参考另一个网络的概率估计来提升自身泛化能力。
接下来我们给出网络的优化策略。对于单块GPU,我们采用交替迭代的方式依次更新两个网络,当有多块GPU时,我们可以采用分布式训练,每次迭代时两个网络同时计算概率估计差异并更新模型参数。实验发现分布式训练可以获得更好的性能。目前关于分布式训练为何能比串行训练获得更好的性能还未有比较好的理论解释,一些研究者认为在分布式训练中每个worker对附近参数空间的探索实际上提高了模型在连续梯度下降方面的统计性能。
我们提出的互学习算法也很容易扩展到多网络学习和半监督学习场景中。当有K个网络时,深度互学习学习每个网络时将其余K-1个网络分别作为教师来提供学习经验。另外一种策略是将其余K-1个网络融合后得到一个教师来提供学习经验 。在半监督互学习场景中,我们对有标签的数据计算监督损失和交互损失,而针对无标签数据我们仅计算交互损失来帮助网络从训练数据中挖掘更多有用信息。
3.实验结果
我们首先在CIFAR-10和CIFAR-100上用不同的网络做了实验,从表中可以看出,所有不同的网络组合采用深度互学习算法均可以提升分类准确率,这表明了我们算法具有较高的灵活性,对网络结构的适应性较强。一般来说小网络从互学习训练中获益更多,比如Resnet-32和MobileNet。尽管WRN-28-10网络参数量很大,与其它网络进行互学习训练依然可以获得性能提升。因此,不同于模型蒸馏算法需要预训练大网络来帮助小网络提升性能,我们提出的深度互学习算法也可以帮助参与训练的大网络来提升其性能。
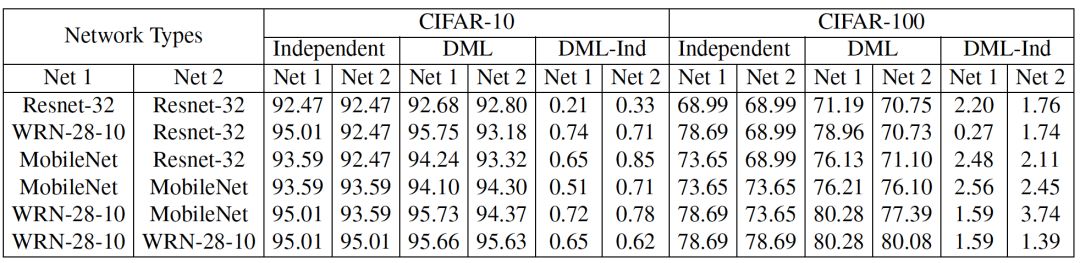
表1 数据集CIFAR-10与CIFAR-100实验结果
我们在ImageNet上也做了实验,从图2中可以看出采用互学习训练均可以提升网络在大规模分类任务上的性能。
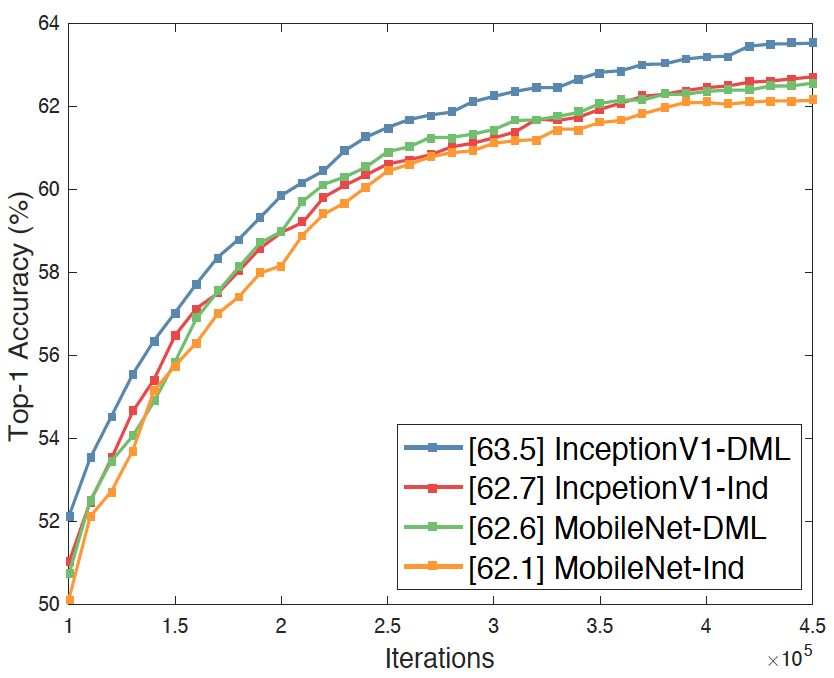
图2 ImageNet实验结果
针对多网络互学习,我们从图3看出增加网络数量可以提升互学习策略下的单个网络性能,这说明更多教师网络提供了更多学习经验,帮助网络学习到更好的特征。另一方面,多网络互学习中多个独立教师(DML)的性能会优于融合教师(DML_e),这说明多个不同教师网络可以提供更多样化的学习经验,更有益于每个网络的学习。
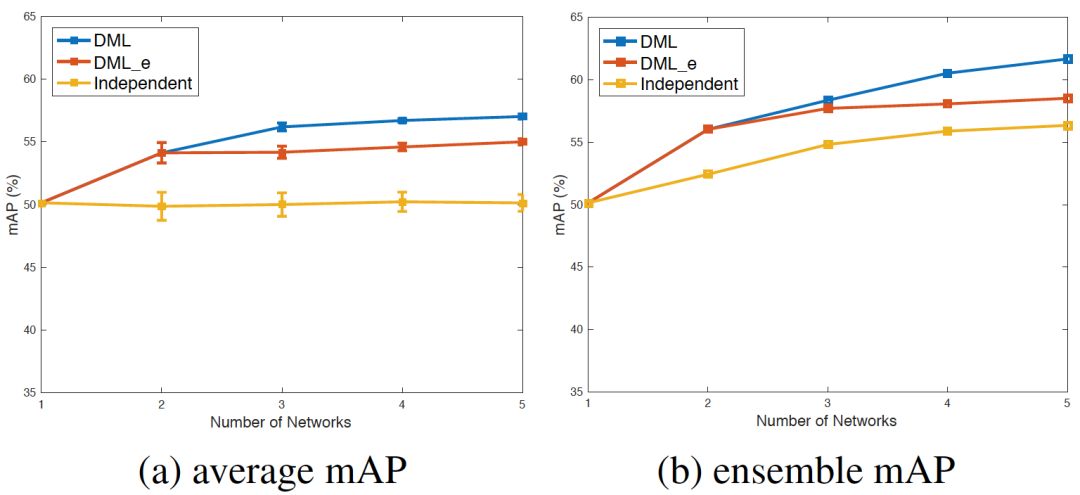
图3 多网络互学习实验结果
针对半监督学习,从图4中可以看出,仅采用有标签数据参与训练时,深度互学习策略可以提高算法分类准确率。而当我们将未标记数据加入互学习训练中,网络的性能可以得到进一步提升,当标记样本数量较少时,其优势更明显。
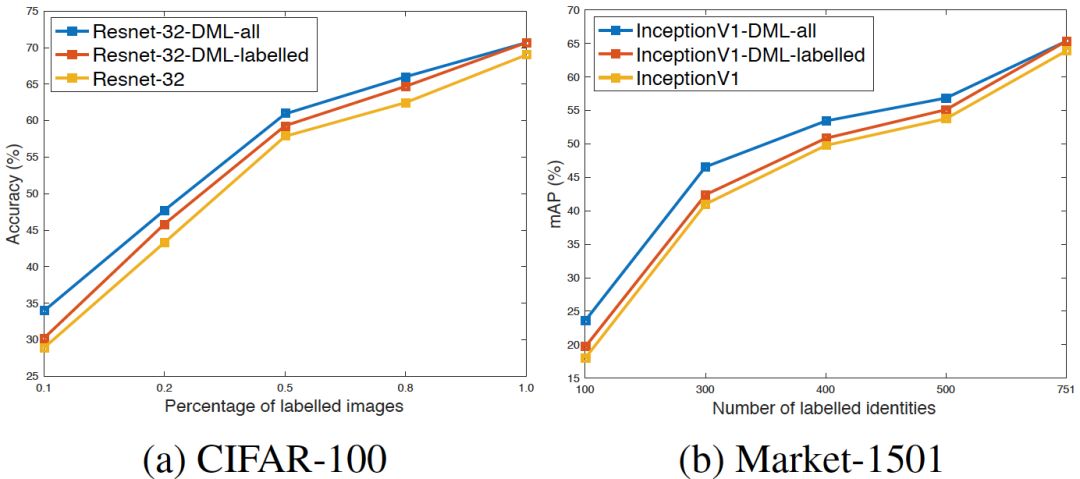
图4 半监督深度互学习实验结果
4.作用机制分析
那么,为什么互学习机制能起作用呢?为什么网络从头开始互学习训练也能收敛到更好的解而不是被互相拉低?当两个网络均从头开始训练时额外的知识从哪里来?为什么约束两个网络的概率估计相近可以提升泛化能力?经过互学习训练后两个网络是不是更相似了?
首先,为什么网络从头开始互学习训练也能收敛到更好的解而不是被互相拉低?直观解释如下:每个网络一开始采用随机初始化,类别概率估计接近于均匀分布,这使得它们在训练初期的监督损失较大,交互损失较小,每个网络主要由传统的监督损失函数引导,这样可以保证网络的性能在逐渐提升。随着模型参数更新,每个网络在自己的学习过程中获得不同的知识,它们对样本类别的概率估计也会有所不同,这时交互损失开始促进网络互相参考学习经验。
接下来是最关键的问题,为什么互学习机制起作用?当两个网络均从头开始训练时额外的知识从哪里来?为什么约束两个网络的概率估计相近可以提升泛化能力?我们从三个角度来尝试理解这些问题。
首先我们认为类别概率估计蕴含了网络挖掘到的数据本质规律。网络的泛化能力越强,则表示网络越有可能挖掘到了数据的内在本质特性,并可以通过类别概率估计表现出来。例如我们希望网络学习区分猫、狗、桌子三个类别,如图5所示,网络在对猫进行分类时除了要最大化猫的类别概率估计,还会给错误类别如狗和桌子分配一定概率,尽管该概率值很低,但我们仍希望分配给狗的概率要大于分配给桌子的概率,即希望网络除了学习到猫的特征,还能学习到和狗共有的一些特征,认为猫与狗的类别距离要小于猫与桌子的类别距离。这样网络在新的测试数据上就更有可能捕捉猫的多种特性,表现出较强的泛化能力。真值标签提供的信息仅包含样本是否属于某一类,但缺少不同类别之间的联系,而网络输出的类别概率估计则能够在一定程度上恢复该信息,因此网络之间进行类别概率估计交互可以传递学习到的数据分布特性,从而帮助网络改善泛化性能。
其次我们认为约束类别概率相近起到正则化作用。深度神经网络在训练过程中一般采用one-hot-vector方式编码真实类别分布,即认为观测样本属于某一类时,其概率值为1,否则为0。InceptionV3论文中认为这种真值标签编码会使得模型在训练过程中对预测结果太过确信,容易导致过拟合,于是提出标签平滑(Label Smoothing)策略,将正确类的概率分配一些给错误类,防止模型把预测值过度集中在较大概率上。Chaudhar等在ICLR2017论文中提出增加熵正则,约束网络预测输出的概率稍微平滑一点。在互学习算法中,当我们将网络2的类别概率传递给网络1时,本质上也是提供额外的类别先验约束,防止网络1过度拟合真值标签的0-1分布,有效降低过拟合发生概率。然而不一样的是,标签平滑和熵正则的类别概率约束是盲目的,而互学习算法中会有更多类别信息。
最后,我们认为网络在训练过程中会参考同伴网络的经验来调整自己的学习过程,最终能够收敛到一个更平缓的极小值点,从而具备更好的泛化性能。关于神经网络泛化性能的一些研究认为,尽管深度神经网络可以找到很多解(即网络学习到的参数)使得训练损失降到零,但一些解能够比其它解具有更好的泛化性能,其原因在于这些解处于更平缓的极小点,这意味着小的波动不会对网络的预测结果造成剧烈影响。
那么我们的深度互学习算法是不是帮助网络找到了一个更平缓的极小点呢?我们进行了实验验证,首先我们观测了两种训练策略下网络在训练数据集上的损失函数变化,从图(a)可以看出单独训练及互学习训练的网络都可以充分拟合训练数据,训练集上的分类准确率都可以达到100%,且训练损失都可以降到几乎相同的极小值。这说明深度互学习算法并没有帮助网络找一个更深的极小值点来帮助网络在训练集上实现损失更小,而是有可能找到了一个深度相同但更平缓的极小值点。
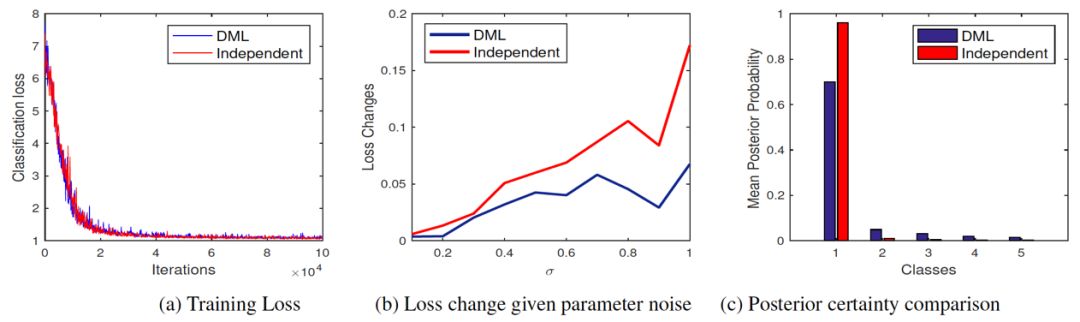
图5 深度互学习作用机制分析
为了验证该猜想,我们对两种策略训练好的网络参数添加高斯噪声,并在图(b)中比较了添加不同方差高斯噪声后网络损失函数值的变化。从图中可以看出,单独训练的网络在添加噪声后损失函数值波动很大,而互学习训练网络的损失函数值则增加很小。该实验现象表明深度互学习算法帮助网络找到了一个更平缓的极小点,针对噪声具有更强的鲁棒性,从而具有更好的泛化性能。
那么深度互学习是如何帮助网络找到更好的解呢? 我们注意到深度互学习算法要求一个网络1的概率估计与同伴网络2的概率估计相匹配,网络1在某个类别上估计概率为为零而网络2估计不为零时,就会产生比较大的惩罚。因此当多个网络参与训练时,每个网络针对样本估计的概率值会分布在不同的类别上,监督损失函数会使得网络在第一最大类上产生较大的概率估计,而剩余的概率值会依次分布在第二最大类及之后的类别上。当两个网络类别概率估计在这些第二类别有差异时,KL损失函数会使两个网络相互妥协,每个网络将分出一些概率值给更接近真值类的第二最大类及之后类别,帮助网络挖掘更多类别信息来找到更好的解。从图上可以看出,采用深度互学习算法可以使得训练集上类别概率分布估计更平缓,且不同类别的相对距离也更明显。
5.结论与展望
我们提出了一个简单有效的互学习算法,通过采用两个网络联合训练来提升深度神经网络的泛化性能。该算法不仅可以用于训练高效的小网络,也可以进一步提升大网络性能,且容易扩展到多网络学习及半监督学习场景中。我们对算法的作用机制进行了探索分析,尝试从网络泛化能力和寻找到解的性质来分析深度互学习算法有效的原因。
代码:
https://github.com/YingZhangDUT/Deep-Mutual-Learning
论文:
http://openaccess.thecvf.com/content_cvpr_2018/papers/Zhang_Deep_Mutual_Learning_CVPR_2018_paper.pdf
编辑:杨茹茵
--end--
该文章属于“深度学习大讲堂”原创,如需要转载,请联系 ruyin712。
作者简介:

张莹,大连理工大学2015级博士生,导师卢湖川教授,研究方向为行人搜索,包括行人再识别和跨模态行人搜索。目前已发表论文9篇,其中第一作者论文5篇,包括2篇CVPR,ECCV等。2016年赴博二期间就读于伦敦玛丽女王大学进行联合培养,指导教师为向滔教授,合作导师Timothy M. Hospedales。
往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘:人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓订阅号

深度学习大讲堂
点击阅读原文打开中科视拓官方网站

