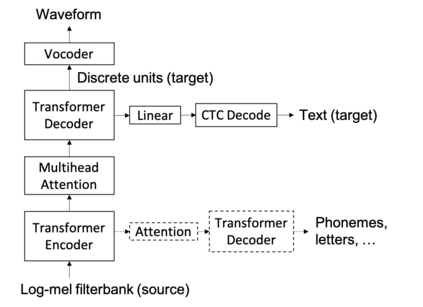
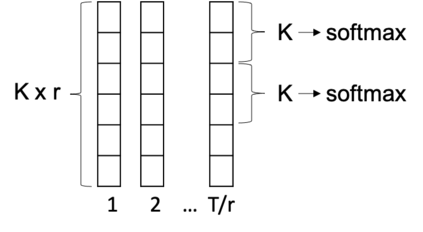
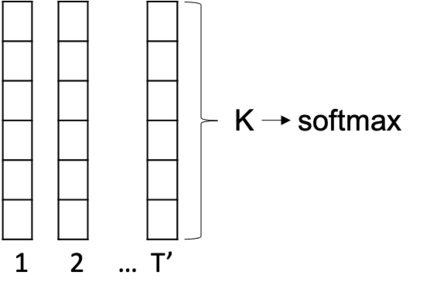
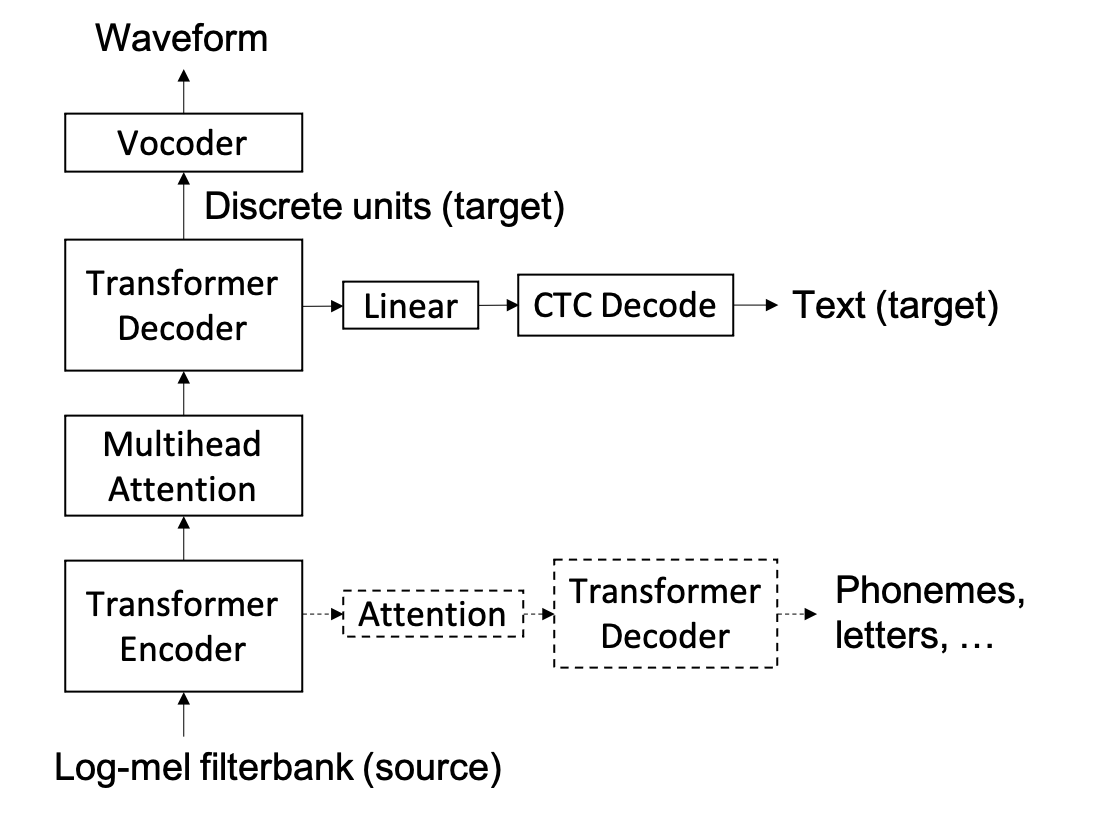
We present a direct speech-to-speech translation (S2ST) model that translates speech from one language to speech in another language without relying on intermediate text generation. Previous work addresses the problem by training an attention-based sequence-to-sequence model that maps source speech spectrograms into target spectrograms. To tackle the challenge of modeling continuous spectrogram features of the target speech, we propose to predict the self-supervised discrete representations learned from an unlabeled speech corpus instead. When target text transcripts are available, we design a multitask learning framework with joint speech and text training that enables the model to generate dual mode output (speech and text) simultaneously in the same inference pass. Experiments on the Fisher Spanish-English dataset show that predicting discrete units and joint speech and text training improve model performance by 11 BLEU compared with a baseline that predicts spectrograms and bridges 83% of the performance gap towards a cascaded system. When trained without any text transcripts, our model achieves similar performance as a baseline that predicts spectrograms and is trained with text data.
翻译:我们提出了一个直接的语音对语音翻译(S2ST)模式,将一种语言的语音翻译翻译成另一种语言的语音,而不必依赖中间文本生成。以前的工作通过培训一个关注的顺序到顺序模型,将语音光谱绘制成目标光谱,来解决这个问题。为了应对对目标演讲的连续光谱特征进行建模的挑战,我们提议预测从无标签的语音材料中学习的自我监督的离散演示。当目标文本誊本可用时,我们设计了一个多任务学习框架,同时进行语言和文本联合培训,使模型能够在同一推论中同时产生双模式输出(语音和文本)。关于渔业西班牙-英语数据集的实验显示,预测离散单元和联合语言与文本数据培训相比,11个语言、语言和文本培训提高了模型的性能,而基线则预测了光谱图,将83%的性能差距连接到一个级联系统。当没有文字誊本的培训时,我们的模型实现了类似的性能,作为基准,预测光谱,并用文字数据培训。