
题目: Wavesplit: End-to-End Speech Separation by Speaker Clustering
摘要:
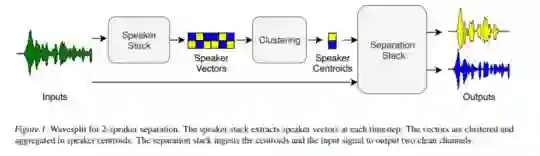
本文介绍了一种端到端的语音分离系统Wavesplit。从混合语音的单一记录中,该模型推断和聚集了每个说话者的表征,然后根据推断的表征估计每个源信号。该模型根据原始波形进行训练,共同完成这两项任务。该模型通过聚类的方法推导出一组说话人表示,解决了语音分离的基本排列问题。此外,与以前的方法相比,序列范围的扬声器表示提供了更健壮的长而有挑战性的序列分离。我们证明Wavesplit在2个或3个扬声器(WSJ0-2mix、WSJ0-3mix)的混合物上,以及在有噪声(WHAM!)和混响 (WHAMR!)的情况下,都比以前的技术水平要好。此外,我们通过引入在线数据增强来进一步改进我们的模型。
成为VIP会员查看完整内容
相关内容

专知会员服务
26+阅读 · 2020年2月16日
专知会员服务
39+阅读 · 2020年1月30日
Arxiv
7+阅读 · 2019年4月18日
Arxiv
5+阅读 · 2019年2月14日



相关VIP内容
专知会员服务
26+阅读 · 2020年2月16日
专知会员服务
39+阅读 · 2020年1月30日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年4月18日
Arxiv
5+阅读 · 2019年2月14日