神经网络机器翻译原理:LSTM、seq2seq到Zero-Shot
本文试图为您深入浅出地讲解机器学习翻译引擎的工作原理,并解释谷歌翻译算法的运作方式。
如果谷歌翻译引擎尝试用较短的句子来翻译,则会因为变量太多而无法进行。理想的状态是教会计算机语法规则,然后让它根据规则翻译句子。可惜并不是这么简单。
饱受学习外语之苦的你肯定知道,规则总是有很多例外。当我们尝试为程序描写所有这些规则及其特例以及特例的特例时,翻译的质量就无从保证。
如今机器翻译系统则使用了不同的方法:它们通过分析大量文本来分配文本中的规则。
我们来看看机器翻译这个“黑匣子”里是些什么东西。深度神经网络可以在非常复杂的任务(语音/视觉对象识别)中取得优异结果,但尽管它们具有灵活性,却只能用于输入和目标具有固定维数的任务。
这就是 LSTMs(Long Short-Term Memory networks)的用武之地了,LSTMs 可以帮助我们无法先验获知的序列。
LSTMs 是一种特殊的循环神经网络(RNN),能够学习长期依赖(long-term dependency)。所有RNN看起来像一连串的重复模块。
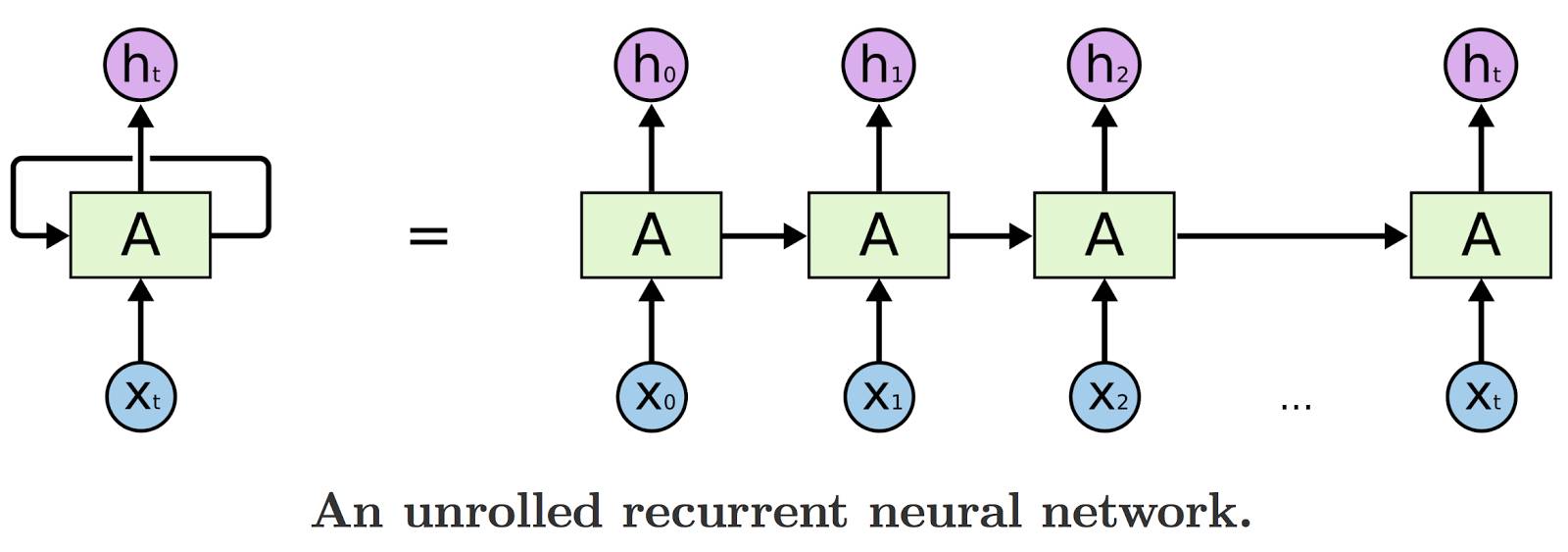
因此,LSTM将数据从模块传输到模块,例如,为了生成Ht,我们不仅用Xt,而且用了所有值为X 的以前的输入。要了解有关LSTM的结构和数学模型的更多信息,您可以阅读“了解LSTM网络“。
下一步是双向循环神经网络(BRNNs)。BRNN 所做的,是将常规RNN 的神经元分成两个方向。一个方向是 positive time,或 forward states。另一个方向是 negative time,或 backward states。这两个状态的输出并不和相反方向状态的输入相连接。
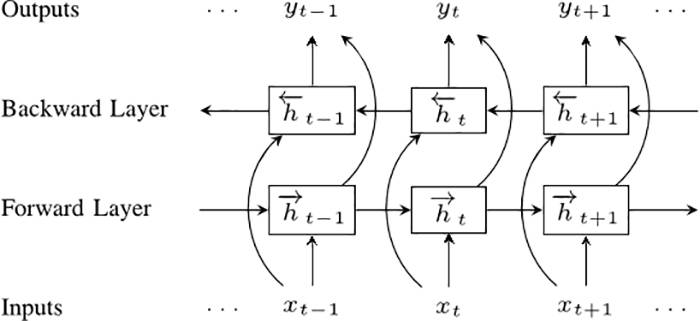
为了理解为什么BRNN 可以简单的RNN效果更好,你可以想象我们有一个9个词的句子,我们想预测第 5 个词。只让它知道前4 个词,和让知道前4个词与最后4 个词——当然,第二种情况下的质量会更好。
接下来就可以说说 sequence to sequence 模型了(也称为seq2seq)。基础的seq2seq 模型由两个RNN 组成:处理输入的编码器网络和生成输出的解码器网络。
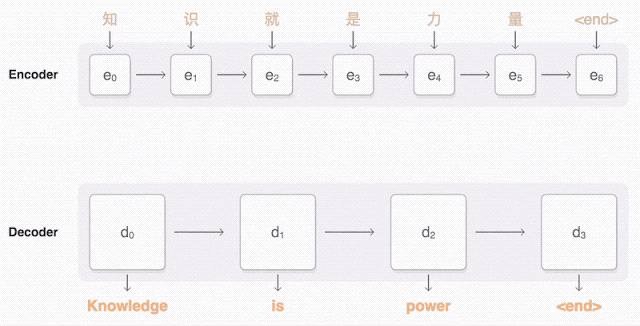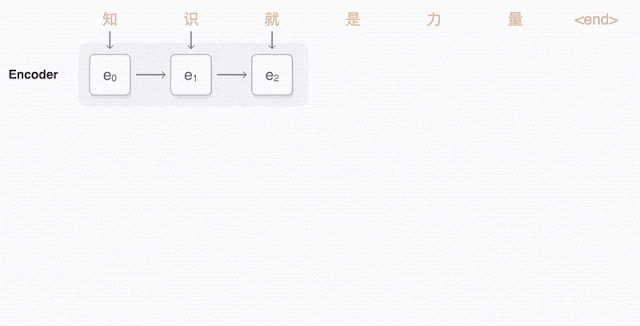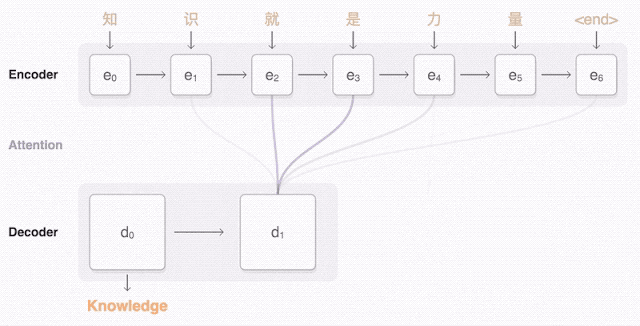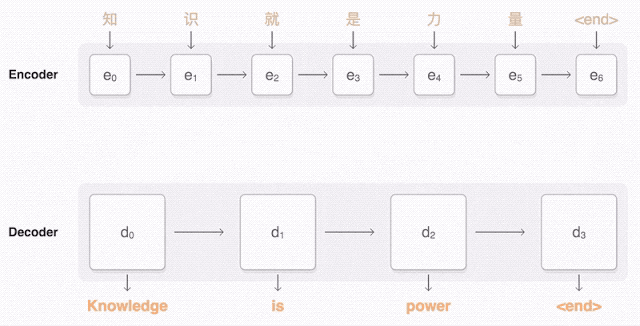
马上,这个机器翻译器就要诞生了!
但是,还有个问题。谷歌翻译目前支持103种语言,难道我们要为每种语言提供103x102种不同的模型吗?当然,这些模型的质量会因为该语言的普及程度和训练这个网络所需的文件数量而有所不同。更明智的方法,是让一个神经网络以任何语言作为输入并转换成任何语言。
这个想法是由谷歌工程师在2016年底实现的。这种神经网络的架构建立在我们刚才说过的seq2seq模型上。
唯一的不同是编码器和解码器之间有 8 层 LSTM-RNN,它们在层之间具有残留连接,并可以在一定程度上做出精度和速度的调整。
这个方法的主要意义在于,现在谷歌算法对于每对语言只使用一个系统,而不是一个庞大的集合。
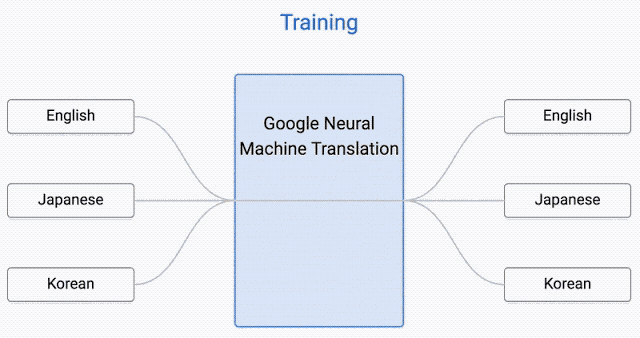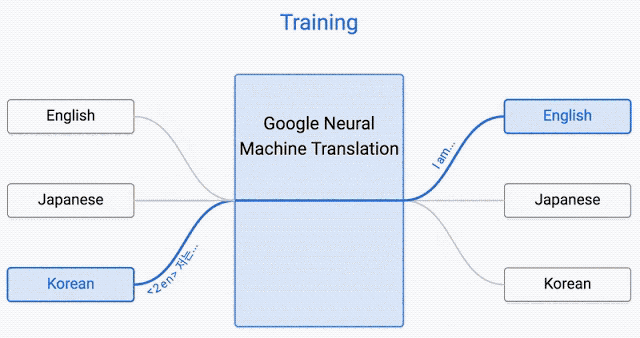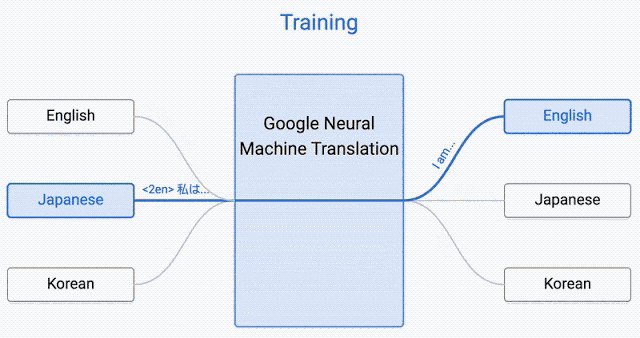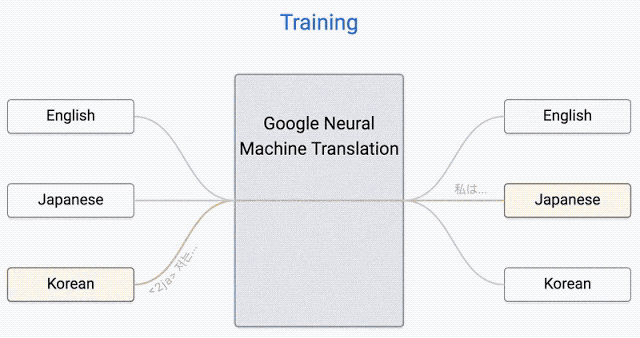
该系统在输入句子的开头需要一个“token”,它指定了您尝试将短语翻译成的语言。
这提高了翻译质量,甚至可以在系统未见过的两种语言之间进行翻译,这种方法称为Zero-Shot Translation。
当我们谈论谷歌翻译算法的改进和更好的结果时,我们如何正确地评估一种翻译比另一种更好?
对于一些常用的句子,我们有专业翻译人员的翻译做参考。
有很多方法部分解决了这个问题,但最流行和最有效的指标是 BLEU (bilingual evaluation understudy)。想象一下,我们有两个机器翻译的备选:
备选 1:Statsbot makes it easy for companies to closely monitordata from various analytical platforms via natural language.
备选 2:Statsbot uses natural language to accurately analyzebusinesses’ metrics from different analytical platforms.

虽然它们具有相同的含义,但质量不同,结构也不同。
我们来看看两个人类翻译的结果:
参考文献 1:Statsbot helps companies closely monitor their data fromdifferent analytical platforms via natural language.
参考文献 2:Statsbot allows companies to carefully monitor data fromvarious analytics platforms by using natural language.
显然,备选 1 更好,与备选 2 相比,它分享了更多的单词和短语。这是 BLEU 方法的核心理念。我们可以将备选的 n-gram 与参考翻译的n-gram 进行比较,并计算匹配数(与其位置无关)。我们仅使用 n-gram 精度,因为有多个参考文献时,计算召回率很困难,结果会是 n-gram 分数的几何平均值。
现在您知道机器学习翻译引擎的复杂性了。下一次当您使用谷歌翻译时,别忘了想像一下,它在返回给您最佳结果之前,已经分析了数百万份文档。






