
题目:GNEG:Graph-Based Negative Sampling for word2vec
论文摘要; 负抽样是分布式词表示学习的一个重要组成部分。我们假设,考虑全局的语料库级信息,为每个目标词生成不同的噪声分布,比原始的基于频率的分布更能满足每个训练词的反例要求。为此,我们从语料库中预先计算单词的共现统计量,并将其应用于随机游走等it网络算法中。我们通过一系列实验验证了这一假设,实验结果表明,我们的方法将单词类比任务提高了约5%,并将单词相似性任务的性能提高了约1%。
成为VIP会员查看完整内容
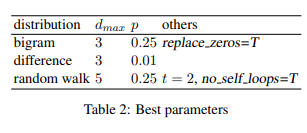
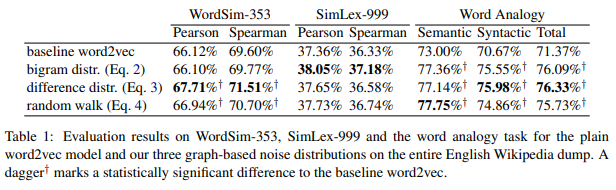
相关内容

专知会员服务
99+阅读 · 2020年7月6日
专知会员服务
58+阅读 · 2020年5月21日
专知会员服务
108+阅读 · 2020年3月29日
专知会员服务
78+阅读 · 2020年3月1日
Arxiv
7+阅读 · 2019年1月18日
Arxiv
17+阅读 · 2017年12月12日




相关VIP内容
专知会员服务
99+阅读 · 2020年7月6日
专知会员服务
58+阅读 · 2020年5月21日
专知会员服务
108+阅读 · 2020年3月29日
专知会员服务
78+阅读 · 2020年3月1日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年1月18日
Arxiv
17+阅读 · 2017年12月12日